
CAP
CAP이론은 일관성(Consistency) , 가용성(Availability), 파티션 허용성(Partition tolerance)의 줄인 말로, 분산 시스템의 기본 원칙 중 하나인데, CAP 이론은 어떤 분산 시스템도 이 세가지 속성을 동시에 만족시킬 수 없다고 주장한다. 동시에 세 가지를 모두 충족하는 것은 불가능하지만, 최대 두 가지 속성만 선택하여 설계할 수 있다고 한다.
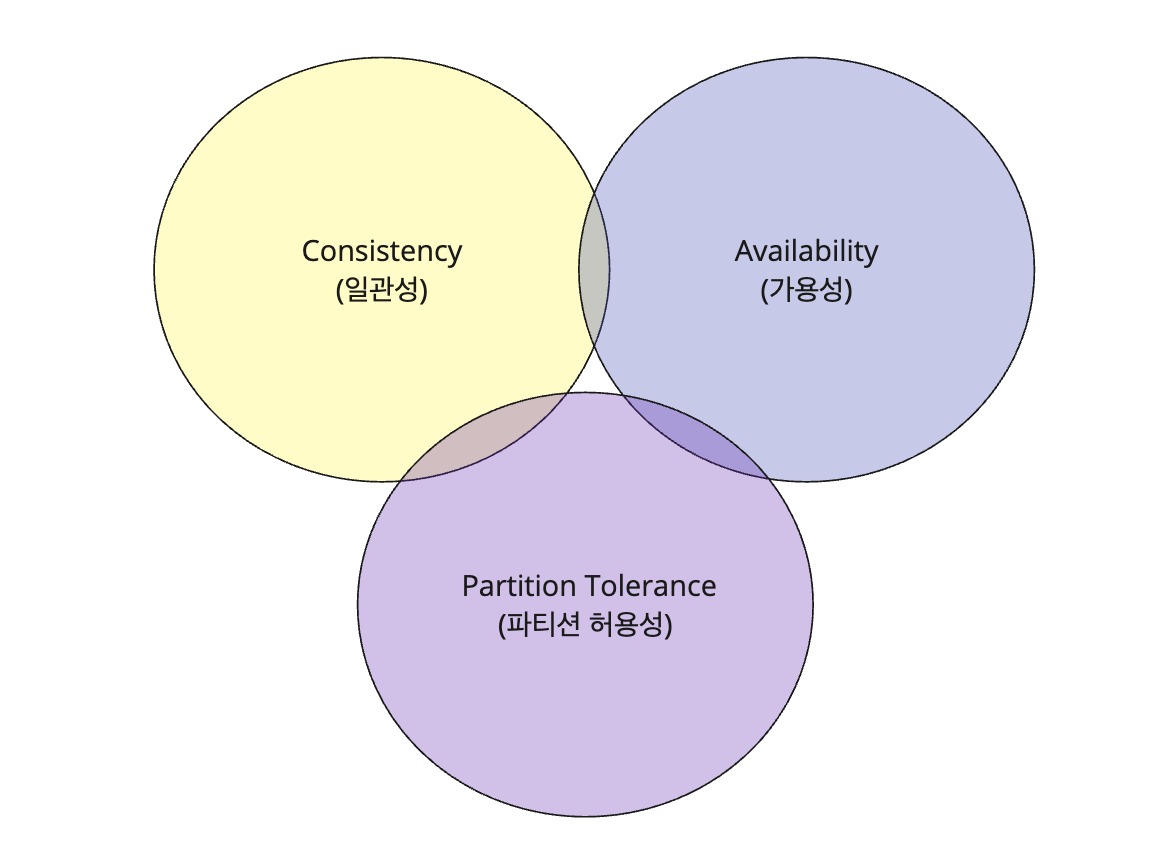
벤다이어그램으로 표현하면 위 그림과 같은데, 자세히 잘 보면 가운데는 겹치지 않는다. 이건 CA(일관성과 가용성), CP(일관성과 파티션 허용성), AP(가용성과 파티션 허용성) 이렇게 2가지 속성 충족 시킬 수 있지만 세 가지 속성을 동시에 만족 시킬 수 없기 때문에 겹쳐지지 않는것이다.
-
일관성 : 모든 노드가 언제나 최신의 데이터를 보유하고 동일한 데이터를 가지고 있어야 한다.
-
가용성 : 모든 정상 요청에 대해 시스템이 적절한 시간 내에 응답을 반환해야 한다. 시스템의 어떤 부분이 실패하거나 네트워크 파티션이 발생해도, 시스템은 계속해서 서비스를 제공할 수 있어야 한다. 즉, 유저가 시스템에 접근할 때 항상 응답을 받을 수 있음을 의미한다.
-
파티션 허용성 : 네트워크 파티션으로 인해 일부 노드 간의 통신이 불가능해도 계속해서 작동할 수 있어야 한다. 실세 분산 시스템에서는 네트워크 문제, 서버 장애 등으로 인해 노드 간의 통신이 중단될 수 있는데, 이러한 상황에서도 시스템은 서비스를 제공할 수 있어야 한다.
분산 시스템에서 파티션 분할은 피할 수 없기 때문에 시스템 설계에서는 일관성과 가용성 중 어떤 것을 우선시 할지를 선택해야 한다.
-
CA(일관성과 가용성) : 파티션을 하지 않고 모든 노드가 항상 최신 데이터를 반환하여 모든 요청에 응답할 수 있게 한다.
-
CP(일관성과 파티션 허용성) : 파티션을 하면서도 일관성을 유지하지만, 일부 요청을 잃어버릴 수 있다.
-
AP(가용성과 파티션 허용성) : 파티션을 하면서 모든 요청에 응답을 하지만, 일부 데이터가 최신 상태가 아닐 수 있다.
사실 CP와 AP는 완벽하게 구현하는 것은 의미가 없다. 일관성, 가용성, 파티션 모두 중요하기 때문에 어느 하나를 완전히 배제하며 시스템을 개발하는 것은 심각한 트레이드오프를 발생시킬 수 있다. 따라서 어떤 시스템을 개발할것인지, 요구사항이 무엇인지에 따라 일관성을 강조하는 동시에 가용성의 일부 제한을 수용하는 등의 방식을 취해야한다.

CAP 이론을 실제로 적용한 예시로 DynamoDB를 보자.
DynamoDB는 NoSQL 데이터베이스로, 높은 가용성과 확장성을 제공하는데 CAP이론에서는 AP(가용성 우선)에 더 가깝게 설계되었다.
-
가용성(Availability) : DynamoDB는 다중 AZ(Availability Zone) 복제를 통해 뛰어난 가용성을 제공한다.
-
파티션(Partition) : 네트워크 파티션이나 서버 장애가 발생해도 데이터베이스 서비스가 계속 작동하도록 설계되어 있으며 데이터는 자동으로 여러 위치에 복제되어 어떤 부분의 시스템이 다운되더라도 전체 시스템의 작동에 영향을 주지 않는다.
-
일관성(Consistency) : 일관성 기능을 기본적으로 제공하지만, 필요에 따라 높은 수준의 일관성으로 수정할 수 있는 옵션을 제공한다.
PACELC
PACELC은 CAP이론에 네트워크 파티션이 발생하지 않는 경우와 발생하는 경우에 대해 추가 한 것이다.
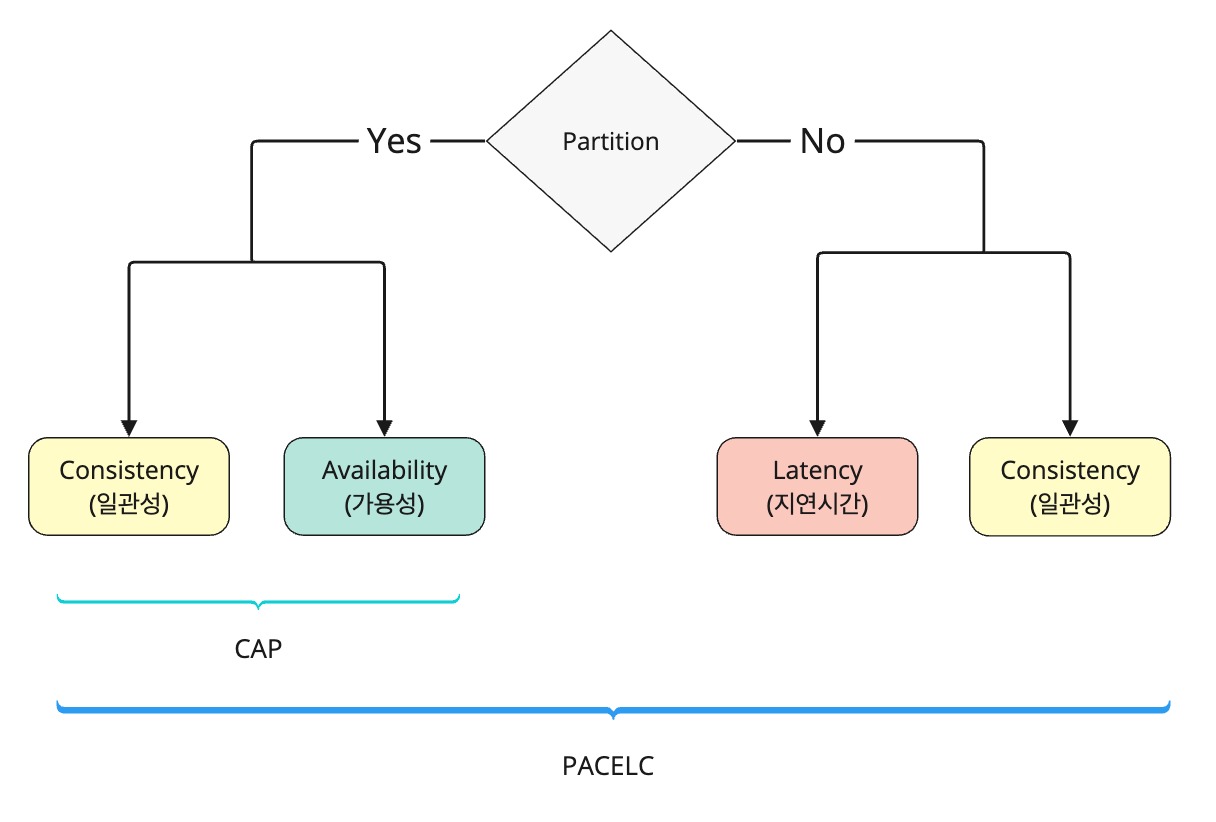
기존 CAP는 Partiton 발생시 Availability와 Consistency 중 하나를 선택해야 했는데, PACELC의 경우 Else가 추가 되어 분할이 발생되지 않는 상황에서도 시스템은 Latency(지연 시간)과 Consistency(일관성) 사이에서 선택해야함을 의미한다.
- 분할(Partition) 발생 시 : CAP 이론과 유사하게, 시스템은 가용성(A)과 일관성(C) 중 하나를 선택해야 한다
- 분할이 없는 경우(Else) : 시스템은 일관성(C)을 유지하면서도 낮은 지연 시간(L)을 제공할 수 있다. 하지만 일관성을 강화하려고 하면 지연 시간이 증가할 수 있고, 반대로 지연 시간을 최소화하려고 하면 일관성 수준이 낮아질 수 있다.
PACELC이론은 분산 시스템 설계를 할 때 네트워크 파티션뿐 아니라, 일반적인 운영 상황에서도 고려해야 할 중요한 트레이드오프를 제시하고 각 시나리오에 대해 더 세밀하게 최적화된 시스템을 설계할 수 있게 한다.
PACELC이론을 실제 적용한 예시로 Apache Cassandra를 살펴보자.
-
분할(Partition) 발생 시 : Cassandra는 Avaliability(가용성)을 우선시 한다. 그래서 파티션을 하더라도 읽기, 쓰기 작업을 계속 수행할 수 있는 AP(가용성 우선) 시스템으로 설계되어 있다. 쓰기 연산 또한 파티션 분할 중에도 여러 노드에 복제될 수 있고, 읽기 연산도 사용이 가능한 노드에서 수행한다.
-
분할이 없는 경우(Else) : Cassandra는 Latency(지연시간)을 최소화하고 일관성을 튜닝할 수 있는 여러 옵션을 제공한다. 따라서 사용자는 읽기, 쓰기 작업에 대한 일관성 수준을 설정할 수 있다.
그래서 Cassandra는 PA/EL을 기본 설정으로 가지고 있지만, 높은 일관성 수준을 요구하는 경우에 수정하여 EC(일관성 우선)으로 수정할 수 있다.
CAP이론과 PACELC이론의 존재 이유는 실제로 분산 시스템과 데이터베이스 설계에서 발생하는 다양한 시나리오와 요구 사항에 대응하기 위함이다. 이 이론들은 분산 데이터베이스 시스템이 직면하는 근본적인 트레이드 오프를 설명한다.
따라서 애플리케이션마다 요구하는 일관성, 가용성, 파티션 허용성, 데이터 모델, 읽기와 쓰기 작업의 비율 , 지연시간 등이 다르기 때문에 해당 이론 이해하고 있으면 애플리케이션 요구에 가장 적합한 데이터베이스를 선택할 수 있다.
예를 들어 은행 시스템은 트랜잭션의 정확성과 일관성을 최우선으로 하지만, 소셜 미디어 피드는 가용성과 읽기 성능을 더 중요시 한다.
결론적으로 CAP 이론과 PACELC 이론은 분산 시스템의 설계와 운영에 있어 필수적인 이론적 배경과 다양한 데이터베이스 기술이 존재하는 이유와 각각이 특정 시나리오에 어떻게 적합한지 이해하는 데 도움을 준다. 이러한 이론을 바탕으로 애플리케이션의 요구 사항을 면밀히 분석하고 최적의 데이터 스토리지 솔루션을 선택하는 것이 중요하다.