
파티셔닝(Partitioning)과 샤딩(Sharding)은 대량의 데이터를 효율적으로 저장하고 처리하기 위한 데이터 분할 방법이다. 두 개념은 유사한 점이 많지만 용도와 구현 방식에서 약간의 차이가 있다.
파티셔닝(Partitioning)
파티셔닝은 단일 테이터베이스 내에서 데이터를 여러 개의 논리적 분할로 나누는 방법이다. 주로 대규모 테이블을 분할하여 데이터 접근 속도와 관리의 효율성을 높이기 위해 사용한다. 파티셔닝은 크게 두 가지 종류가 있으며 수직 파티셔닝(Vartical Partitioning)과 수평 파티셔닝(Horizontal Partitioning)로 나눌 수 있다.
- Vartical Partitioning : Column을 기준으로 Table을 나누는 방식
- Horizontal Partitioning : Row를 기준으로 Table을 나누는 방식
Vartical Partitioning
수직 파티셔닝은 기존 테이블을 열(Column) 단위로 여러 테이블로 나누어 저장하는 방식이다.
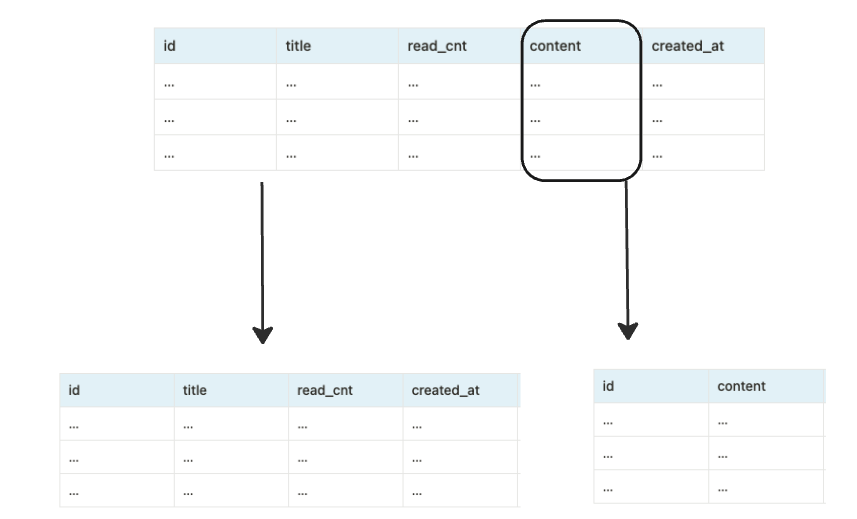
위 이미지처럼 수직 파티셔닝을 하게 된다면 기존 테이블의 크기를 줄이고, 특정 열에 대한 쿼리 성능을 향상시킬 수 있다. 수직 파티셔닝은 주로 자주 사용하는 데이터와 덜 사용하는 데이터로 분리하거나 큰 데이터를 별도로 관리하는데 사용하지만 민감한 데이터를 별도로 테이블로 저장하여 접근 제어 역할도 가능하다. 나눠진 테이블은 원래 테이블과 동일한 행(row)를 공유하고 고유 식별자(primary key)를 기준으로 연결된다
장점
- 자주 사용하는 열만 있는 테이블에서 데이터 읽어서 성능이 빠름
- 민감한 데이터를 별로도 저장하기 때문에 보안이 좋음
- 서로 다른 열을 사용하는 작업이 동시에 실행되도 충돌 없이 병렬 처리가 가능하고, 이로 인해 테이블 Locking 가능성이 줄어든다.
단점
- 데이터를 다시 결합할때 조인에 대한 비용
- 데이터를 어떻게 분리할지에 대한 설계 비용이 상당함
- 테이블과 테이블관의 관계 설정을 잘못하면 데이터 무결성이 깨질 수 있음
Horizontal Partitioning
수평 파티셔닝은 데이터를 행 단위로 나누어 저장하는 방법이다. 데이터베이스의 크기가 너무 커질 경우 성능 저하를 방지하거나 특정 데이터를 조회할 때 효율을 높이기 위해 주로 사용된다. 데이터를 하나의 테이블에 모두 저장하는 대신 특정 기준에 따라 행을 여러 파티션으로 나누기 때문에 모든 파티션은 동일한 열 구조를 유지하고 파티션별로 데이터를 관리하기 때문에 파티션별로 독립적인 관리를 할 수 있다.

수평 파티셔닝의 간단한 예시로는 주문 테이블을 날짜별로 나누거나 카테고리별로 데이터를 나누는 것이 있다.
정점
- 특정 파티션에만 쿼리를 실행하기 때문에 검색 속도가 빠름
- 데이터가 커질수록 새로운 파티션을 추가하여 확장할 수 있음
- 파티션별로 병렬처리가 가능해서 성능 향상
- 오래된 데이터를 특정 파티션으로 아카이브하거나 삭제하거나 등 데이터 관리가 편함
- 백업이나 복구에도 필요한 파티션에만 처리할 수 있음
단점
- 분할 기준이 잘못되면 특정 파티션에 데이터가 몰림
- 일부 쿼리는 여러 파티션에 컬쳐 실행되어서 성능이 저하댈 수 있음
- 테이블의 크기가 커질수록 인덱스의 크기도 커짐
파티셔닝 분할 기준
수평 파티셔닝에서 어떻게 데이터를 나눌지에 대한 분할 기준은 아래와 같다.
-
범위 파티셔닝
- 데이터를 범위(range) 기준으로 나누는 방식
- 주로 날짜, 숫자, ID와 같은 연속적인 값을 가진 데이터에 적합
- 시간 기반 데이터에 조금 더 적합(로그, 주문 데이터)
- 각 파티션은 특정 값의 범위를 담당하므로 조건에 맞는 데이터만 해당 파티션에 저장함
-
리스트 파티셔닝
- 데이터를 특정 값 목록(List) 기준으로 나누는 방식
- 범위가 아닌 명확한 값에 따라 데이터를 나눌 때 적합
- 주로 카테고리/지역 등 고정된 값의 데이터에 활용
- 국가/제품 카테고리 등
- 이럴 경우 단점으로 리스트에 정의되지 않은 입력값이 들어오면 오류가 발생할 수 있음
-
해시 파티셔닝
- 데이터를 해싱(hashing) 함수의 결과에 따라 나누는 방식
- 특정 값(id)를 해싱하여 각 파티션에 고르게 분배
- 데이터가 고르게 분산되도록 설계되었기 때문에 데이터 불균형 문제를 해결하는데 유용
- 대신 해싱 함수 변경 시 전체 데이터 재배치 필요하기 때문에 설계 초기에 신중해야 함
-
조합 파티셔닝
- 두 가지 이상의 분할 기준을 결합하여 데이터를 나누는 방식
- 예를 들어 범위와 해시 파티셔닝을 사용한다고 하면
- 연도별로 데이터를 나눈 뒤 각 연도의 데이터를 해싱하여 분배
- 예를 들어 범위와 해시 파티셔닝을 사용한다고 하면
- 두 가지 이상의 분할 기준을 결합하여 데이터를 나누는 방식
수직 파티셔닝은 열(Column)기준으로 데이터를 나누기 때문에 위의 분할 기준은 사용하지 않는다.
Sharding
샤딩은 파티셔닝처럼 동작하지만 파티셔닝과 다른 점은 각 파티션을 독립된 데이터베이스 서버에 저장한다. 각 파티션을 서로 다른 DB서버에 저장하여 부하를 분산시키는 것이 샤딩의 목적이기 때문에 아래와 같은 그림으로 파티셔닝과 샤딩을 정리할 수 있다.

샤딩도 파티셔닝과 마찬가지로 수직 샤딩(Vartical Sharding)과 수평 샤딩(Horizontal Sharding)이 있고 수직 샤딩은 수직 파티셔닝과 마찬가지로 열(Column) 단위로 나누거나 더 큰 범위에서는 기능 단위로 데이터 베이스를 분리한다. 예를 들어 사용자 데이터베이스 / 주문 데이터베이스 / 상품 데이터베이스 등 이렇게 기능별로 분리해서 각각 다른 테이블이나 데이터베이스에 저장한다. 수평 사딩도 수평 파티셔닝과 마찬가지로 테이블의 행을 기준으로 데이터를 분할하기 때문에 동일한 스키마를 가지고 데이터를 나눠서 저장한다.
장점
- 어플리케이션에서 기능별 데이터 접근이 명확해짐
- 데이터베이스 관리가 비교적 단순
- 데이터가 증가해도 샤드를 추가하면 쉽게 확장 가능
- 각 샤드의 데이터가 균등 분배되어 성능 안정적
단점
- 샤드 간의 조인이 필요한 경우 성능 저하
- 특정 테이블이 너무 커지면 별도의 확장이 필요
- 샤드 간의 트랜잭션 관리
- 샤드 키가 잘못 설계되면 특정 샤드에 데이터가 몰림
- 샤딩은 샤드 키를 기반으로 라우팅하기 때문에 샤딩 로직을 구현해야 함
요약
- 파티셔닝의 목적은 데이터를 논리적으로 분리하여 효율성을 높이는 것
- 하나의 데이터베이스 내에서 성능과 데이터 관리를 최적화하는 것이 목표
- 샤드의 목적은 부하를 분산 시키는 것.
- 각 파티션을 서로 다른 데이터베이스 서버에 저장하여 부하를 분산
- 데이터가 너무 많아서 단일 데이터베이스로 감당하기 힘들 때 사용