
강화학습은 시행착오를 통해서 환경에 적응하는 학습 방법을 이야기합니다. 지도학습과는 다르게 이 행동이 맞다는 것이 명시적으로 주어지는 것이 아니라, 보상을 통해 행동의 바람직함을 스스로 알아가는 학습 방법입니다.
강화학습에서 사용하는 용어
강화학습에서는 크게 6가지의 용어가 있습니다.
- 1. 에이전트: 강화학습을 통해 학습하는 컴퓨터. 학습의 주체
- 2. 환경: 에이전트가 행동하는 곳
- 3. 상태: 에이전트가 처한 특정한 상황에 대해 관찰
- 4. 행동: 에이전트가 어떠한 상태에서 취할 수 있는 행동
- 5. 보상: 행동에 대한 보상
- 6. 정책: 에이전트가 보상을 얻으려면 행동을 해야한다. 특정 상태가 아닌 모든 상태에 대해 어떤 행동을 해야하는지 알아야 하는데 이렇게 모든 상태에 대해 에이전트가 어떤 행동을 해야하는지 정해 놓은 것
여기서 보상은 강화 학습이 다른 머신러닝 기법과 다르게 만들어주는 가장 핵심적인 요소이며 보상에는 즉각적 보상과 최종 보상 등이 있습니다.
바둑이 왜 인공지능의 위대한 도전인가?
바둑은 경우의 수가 매우 많습니다. 한 게임에서 평균적으로 바둑판에 둘 수 있는 점은 250개이며 게임이 평균 150수까지 진행된다고 할 때, 총 경우의 수느느 250의 150승입니다. 즉, 10의 360승개의 경우의 수가 있습니다. 이 뜻은 우주의 원자의 개수인 10의 80승보다도 많고 체스 10의 123승보다 많으며 비교도 할 수 없을 정도로 큰 경우의 수입니다. 아무리 슈퍼 컴퓨터를 수만대 동원하더라도 모든 경우의 수를 따져서 승리를 보장하는 최적의 수는 찾기 불가능합니다.
그렇기 때문에 강화학습으로 인공지능을 알린 것이 대단하다고 하는 것입니다.
바둑 프로그램은 사실 1960년대부터 연구를 했으나, 위의 경우의 수 때문에 5급 정도의 아마추어 수준에 머물었다고 합니다. 여기서 min/max 트리 알고리즘이라는 것이 나온 후 업그레이드가 되었지만 min/max 트리를 바둑의 트리로 표현하면 250의 150승 노드를 갖게 되므로 모든 노드를 탐색하는 것은 사실상 불가능합니다.
그리고 2008년에 몬테카를로 트리 탐색기법이 적용되면서 바둑 5단으로 비약적인 수준으로 상승했다고 합니다.
이세돌과 대결한 알파고의 원리
어떻게 알파고는 바둑을 학습했을까요 ? 알파고는 총 3단계에 거쳐서 학습을 했다고 알려져 있습니다.
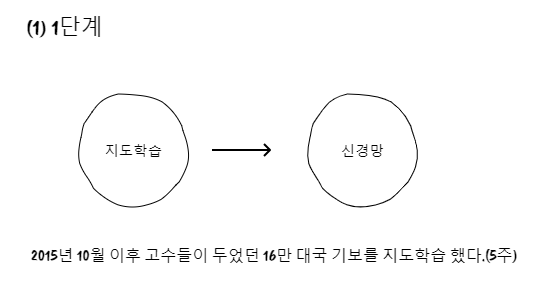
바둑은 19x19이며, 흑백의 착수 순서만 입력해서 신경망을 만들었는데, 다음 수를 예측하는 이 신경망의 정확도가 55.7%가 나왔다고 합니다. 여기서 2단계에 강화학습을 입혔다고 합니다.
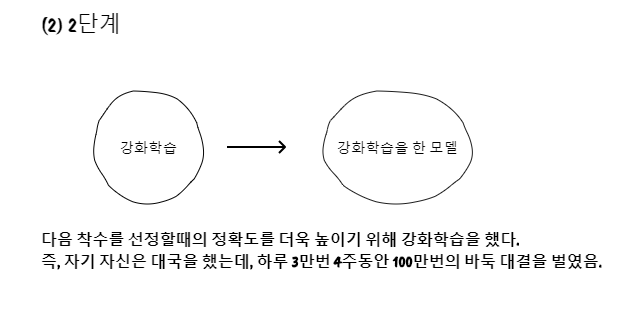
알파고는 강화학습을 통해 스스로 공부하며 깨우치는 학습 능력을 갖추게 되었습니다. 사람이 100만번의 대국을 치를려면 1000년 이상 걸린다고 하는데, 4주동안 한거면 정말 대단한것을 알 수 있습니다. 마지막으로 3단계는 몬테카를로 트리 탐색와 가치망입니다.
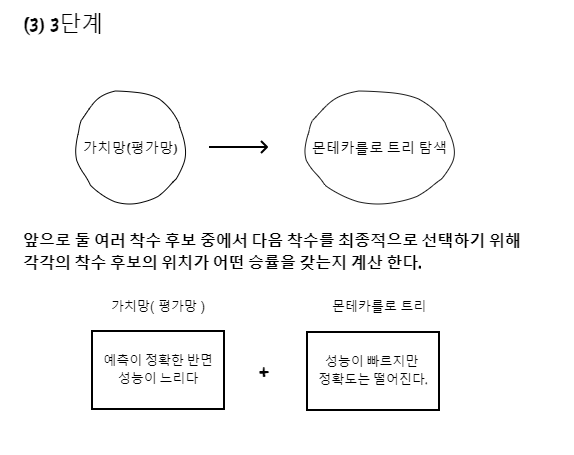
이 두가지 기법의 장단점을 보완하기 위해 위의 2가지 결과를 50%씩 반영하여 최종 착수 위치를 결정한다고 합니다. 이렇게 보니 강화학습이 정말 대단하고 알파고가 얼마나 똑똑한지 조금은 와닿는 것 같습니다.