
샘플링과 리샘플링은 여러곳에 다양하게 사용되기 때문에 알아둬야 한다. 샘플링과 리샘플링에 대해 간단하게 알아보자.
샘플링(Sampling)
샘플링은 모집단에서 임의의 Sampling을 뽑아내는 것으로, 쉽게 말해 표본 추출을 의미한다. 샘플링을 하는 가장 큰 이유는 모집단 전체에 대한 조사는 사실상 불가능하기 때문에 Sampling을 이용하여 모집단에 대한 추론을 하게 되는 것이다. 주로 머신러닝과 통계분야에서 흔히 볼 수 있으며 신뢰구간, 오버피팅, 분산 등 밀접한 관련이 있다.
여기서 알아둬야 할 것은 표본은 모집단을 닮은 모집단 mirror 같은 존재이지만, 모집단 그 자체는 아니다. 그렇기 때문에 표본에는 반드시 모집단의 원래 패턴에서 놓치는 부분이 존재 할 수 밖에 없다.
리샘플링(Resampling)
리샘플링은 내가 가지고 있는 샘플에서 다시 샘플 부분집합을 뽑아서 통계량의 변동성을 확인하는 것을 이야기한다. 즉, 같은 샘플을 여러 번 사용해서 성능 측정하는 방식이다. 가장 많이 사용되는 방법이며 종류로는 k겹 교차 검증, 부트스트래핑이 있다.
- k-fold
k-fold는 k-1개의 부분집합들을 훈련 세트로 사용하고 나머지 하나의 부분집합을 테스트 세트로 사용하는 것을 말한다. 이렇게 하면 아래의 그림처럼 k개의 훈련/테스트 세트가 만들어지고 k번의 훈련과 테스트를 거쳐 k개의 테스트 결괏값의 평균을 얻을 수 있다.
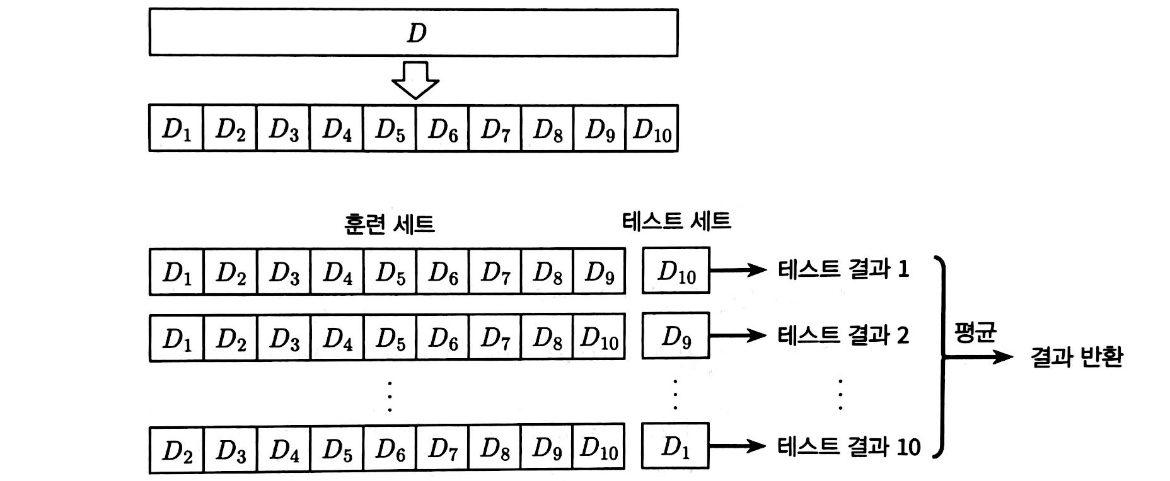
당연한 이야기이지만, 평가 결과와 안정성과 정확도는 k값에 따라 달라진다. 일반적으로 k는 10으로 두고 검증하며, 10외에 5, 20이란 값도 자주 사용된다. 그리고 샘플을 나누는 과정에서 생길 수 있는 차별을 최소화 하기 위해 일반적으로 p번을 랜덤하게 반복하여 나누어 진행한다. 즉 k-fold는 최종적으로 p번의 k겹 교차 검증을 실행한 값의 평균을 말한다. 주로 10차 10겹 교차검증을 사용한다.
- 부트스트래핑
부트스트래핑(bootstrapping)은 m개의 샘플이 있는 데이터 세트 D를 가정한다면, 우리는 샘플링을 통해 데이터 세트 D’를 만든다. 매번 D에서 샘플 하나를 꺼내 D’에 복사하여 넣는다. 그리고 다시 원래의 데이터 세트 D로 돌려보낸다. 이러한 과정을 m번 반복한 후 우리는 m개의 샘플이 들어있는 데이터 세트 D’를 얻는다. 이것이 부트스트래핑의 결과이다.
그러나 어떤 샘플은 아예 뽑히지 않을 수도 있는데, 수학적으로 계산하면 m번의 채집 과정 중 샘플이 한 번도 뽑히지 않을 확률은 (1 - 1)m/m이다. 극한값을 계산해본다면 아래와 같이 할 수 있다.
즉, 부트스트래핑을 사용하면 데이터 세트 D중 36.8%의 샘플은 D’에 들어기지 못하기 때문에 D’를 훈련 데이터로 D-D’를 데이터 세트로 사용할 수 있다. 이러한 테스트를 Out-of-Bag이라고 한다.
아무튼 데이터를 어떻게 나누어 검증하냐에 따라 모델 성능이 천차만별이나 주의하자..