
Paper URL: https://arxiv.org/abs/2009.07769
해당 논문은 오픈소스로 공개되어 있다. 이 논문에서는 새로운 GAN 아키텍처인 TadGAN을 소개하며, 새롭게 Anomaly Scores를 계산하는 방법을 제안하였다.
이상감지
논문에서 이상감지하는 방법에는 여러가지가 있다고 한다.
- 시계열 패턴을 학습.
특정 부분을 이상 감지하도록 요청. 사용자와 관련된 것을 학습했는지 확인하도록 모델을 훈련. - 정상 데이터에 대해 정상 기준선을 제공하여 모델과의 편차가 비이상적으로 큰 데이터 패턴을 학습
- 시계열 패턴의 유사성을 판단
- K-Nearest Neighbor(KNN) 으로 데이터를 묶어서 정위하고 이웃수를 이상점수를 결정하는데 사용.
그러나 시간적 상관 관계를 포착하기 힘들기 때문에 사용못함. - 예측 모델을 사용하여 예측하는 방법.
도메인 지식 필요.
그러나 감지된 모든 이상이 문제가 되는 것은 아니다. 그렇기 때문에 모델에 의해 식별된 이상이 문제인지에 대한 평가는 도메인 전문가 또는 최종 사용자의 몫이라는 것을 기억해두자.
TadGAN
TadGAN의 아키텍처는 아래와 같다.
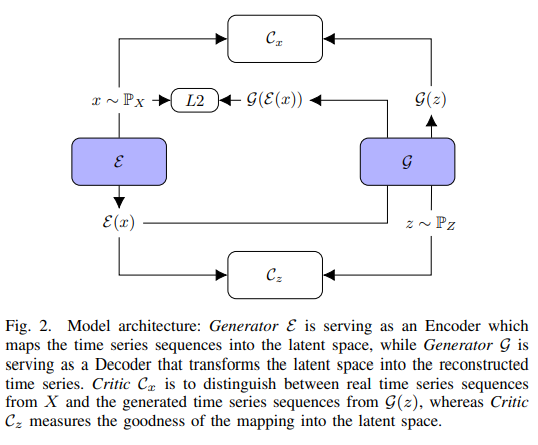
TadGAN에서는 함수 2가지만 기억하면 되는데, Reconstruction Errors와 Critic outputs이다.
1. Reconstruction Errors Reconstruction Errors $𝑅𝐸(𝑥)$는 3가지 유형의 함수가 있다. 학습 시킬때 전부다 사용하지는 않고 해당 함수 중 하나를 선택한다.
- Point-wise difference
실제 데이터 $x^t$ 에서 예측 값 $\hat{x} ^t$ 를 빼서 차이를 계산.$st = |{x}^t - \hat{x}^t |$ - Area difference
특정 구간의 유사성을 판별하기 위해 특정 길이에서 영역 비교
$st = \frac{1}{2*l}\left | \int_{t-1}^{t+1} {x}^t - \hat{x}^t dx \right |$ - Dynamic time warping (DTW)
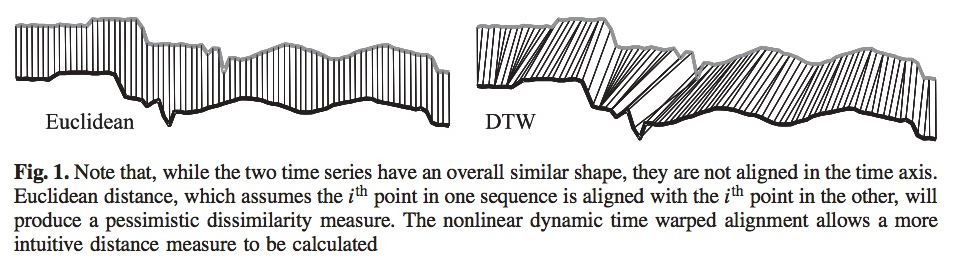
다른 2개의 시계열 패턴의 유사성을 비교할 때 사용하는 알고리즘.${W}^* = DTW(X, \hat{X}) =\underset{W}{min} \left | \frac{1}{K}\sqrt{\sum_{k=1}^{K}}w_k \right |$ 예를 들면, 두 개의 목소리를 비교해서 동일인 인지 확인하는 것. 동일인이 말하더라도 천천히 말할 때와 빨리 말할 때가 다름. 그래서 DTW에서는 거리가 가장 짧은 시점(유사도가 높은 시작점)을 찾는다.
2. Critic Outputs 𝐶𝑥(𝑥)
Critic $c_x$는 0에서 1사이의 확률 값을 가지며 진짜일 확률을 나타내며, Critic Outputs에 KDE를 취한 다음 maximum을 평활화 (smoothed value) 를 시킨 값이 Critic scores이다.
여기서 KDE(kernel density estimation)에 대해 잠깐 설명하자면, 데이터를 바탕으로 하는 밀도 추정으로 데이터마다 커널을 생성한 히스토그램이다.
최종적으로 만들어진 함수는 위 $𝑅𝐸(𝑥)$ 와 Critic outputs $𝐶𝑥$를 합친 것이다.
그러나 $RE(x)$와 Critic outputs $C_x$를 직접적으로 함께 사용할 수 없다. 왜냐하면, $RE(x)$는 클수록 anomaly scores가 높은 거고, Critic outputs $C_x$는 낮을수록 anomaly scores가 높기 때문이다. 그래서 $RE(x)$와 Critic outputs $C_x$에 평균과 표준편차를 취했고, 각각의 z-scores에 넣고 계산 한 다음 정규화를 취했다. 이렇게 되면 z-scores가 높게 나오게 될 경우 anomaly scores가 높다고 할 수 있기 때문이다.
최종적으로 만들어진 스코어 함수는 아래와 같다.
모델애 대한 성능은 아래 표와 같다.
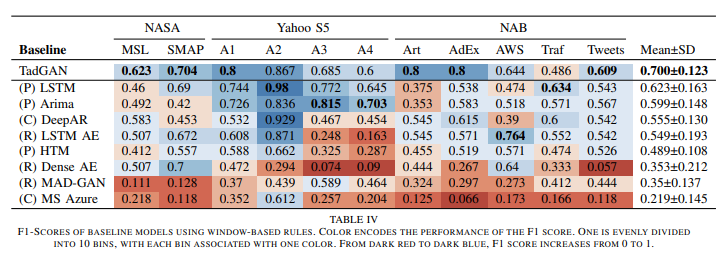
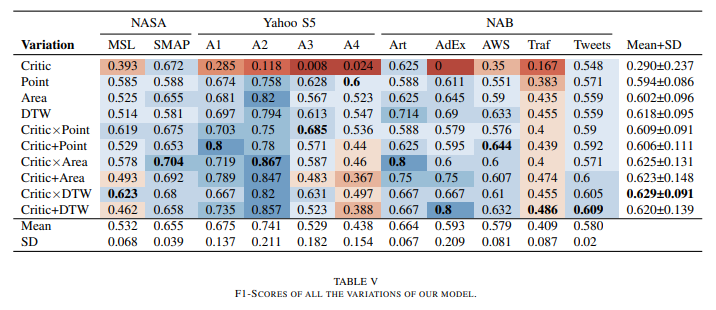
아래는 함수에 따른 성능 표이다.
결론
GAN은 데이터 분포를 학습하기 때문에 False 알람을 많이 유발 시킬 수 있다. 오픈소스를 이용하여 실 데이터에 적용해보았을 때, 성능이 나쁘지는 않았지만, 생각보다 수정해야 할 부분이 많았다… ㅋㅋㅋㅋㅋ
좋았던 부분이 하나 있었는데, GAN모델이기 때문에 generator값을 보며, score나 error값이 왜 이렇게 떨어지는지에 대한 설명력이 조금 생겨서 일반인들에게 설명할 때 편하다는 점이 좋았다.