
Paper URL : https://arxiv.org/pdf/1611.07004.pdf
Pix2Pix논문에 대해 리뷰 해볼까한다. 2018년도에 나온 논문이고 상당히 유명한 모델이다. 이번 논문 리뷰에서는 GAN에 대한 기본 개념은 어느정도 있다고 생각하고 글을 썼으니, 혹시나 헷갈리는 부분이 있다면 다시 한번 보고 오기를 바란다.
요약
- 다양한 image-to-image translation task를 수행하는 general-purpose GAN을 제안했다.
- 네트워크 구조나, 목적 함수에 변경 없이 다양한 이미지 변환 task를 수행할 수 있다.
- 저자들은 이를 ‘모델이 데이터에 적응하는 loss를 학습한다’ 라고 표현하고 있다.
- convolutional conditional GAN을 backbone으로 하였고, 목적함수에 L1 loss 추가하였다.
- 구체적으로 generator는 U-Net구조, discriminator는 patchGAN을 사용하였다.
Introduction
이미지 변환에 대한 과거 연구들은 모두 task마다 별도로 세분화된 모델/기술을 사용하여 문제를 해결하였다.

논문의 저자들은 이미지 변환이라는게 결국 from pixels to pixels 라는 하나의 공통된 세팅하에 수행된다는 사실에 주목하였다. 그래서 모든 이미지 변환 task들을 해결할 수 있는 common framework를 제안하는 것을 목적으로 연구했다.
automatic image-to-image translation : 어떤 한 장면에 대한 representation을 다른 representation으로 바꾸어 표현하는 task.
Objective
저자들은 이전 연구인 GAN의 main objective에서 L2 distance등의 전통적인 loss를 추가하는 것이 이로움을 확인하였다. (아래 그림 수식(1))

특히 generator가 ground truth output에 pixel단위로 더 비슷해지게 만드는 효과가 있는데, L2보다 L1이 결과가 덜 blurring해서 저자들은 L1 distance를 사용했다고 한다.
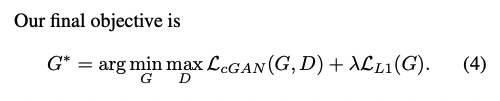
그 결과 생성 이미지의 결과가 완전 deterministic해졌다.(동일한 Input을 넣으면 항상 동일한 Output이 나옴). 저자들은 여기에 약간의 stochastic을 추가하기 위해 dropout을 train/test time 모두에 작동하도록 세팅하였다. 하지만 큰 랜덤성은 확보하지 못했다는 limitation이 남아있다.
Model
-
Generator
저자들은 Encoder-decoder 네트워크를 토대로 level별로 처리된 feature들의 정보를 효율적으로 이용할 수 있도록 connection을 추가한 U-Net구조를 generator의 아키텍쳐로 사용하였다.
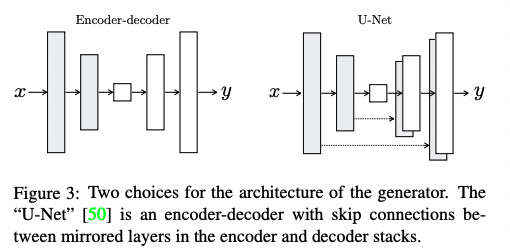
-
Discriminator
L2와 L1 Loss는 계산될때, 모든 픽셀값들에 대해 averaging되기 때문에, image generation시 high-level 특성을 잘 살리지 못하고 blurry한 결과를 줄 수 있다.
그러나, L2, L1 손실들은 low-level 특성은 정확하게 잘 포착해낼 수 있다
따라서 discriminator의 구조를 고려할 때, 저자들은 high-level structure를 잘 살려낼 수 있도록 하는 모델을 선택할 필요가 있었고, PatchGAN의 discriminator를 사용하게 되었다.
-
Optimization & inference

최적화 시키기 위해 모델은 discriminator 한번, generator 한번 번갈아 학습하였고, $log(1-D(x,G(x,z))$를 최소화하는 대신 $logD(x,G(x,z))$를 최대화하는 방향으로 학습하였다. $D$를 최적화하는 동안 목적함수를 2로 나눠서 G와 비교한 상대적 학습률을 조금 늦췄으며, 파라미터는 Adam, lr=0.0002, beta1=0.5, beta2=0.999이다. 특이하게, inference시에도 train시와 동일하게 적용되도록 dropout이나 bn등이 train mode로 작동하게 하였다.
-
Conclusion

결과물만 확인해보면 질적인 실험결과는 cGAN이 세그멘테이션을 잘 수행함을 보여주고 있다.
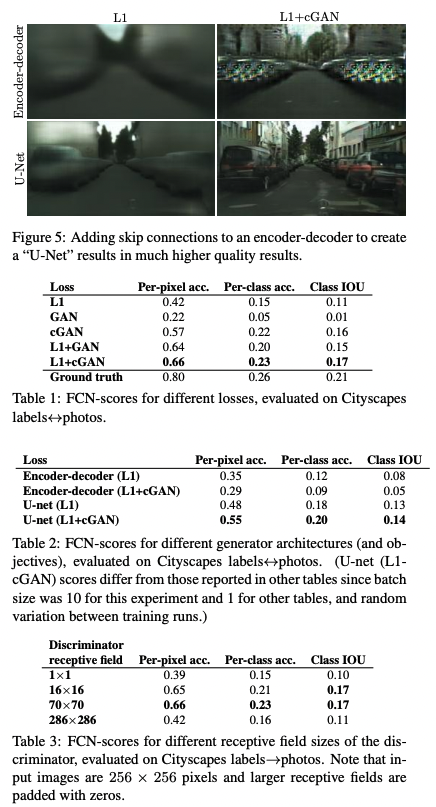
그러나 양적인 실험결과는 오히려 단순히 노말 GAN+L1 Loss를 사용하는 편이 정확도 등의 측면에서는 더 나음을 보여준다.