
Paper URL : https://arxiv.org/pdf/1606.06650v1.pdf
보통 3D 데이터 셋을 이용해 모델을 만들고자 했을 때, 3D데이터를 잘게 슬라이스하여 2D 데이터로 만들어 사용한다고 한다.
대부분의 경우 잘 작동하겠지만, 많은 3D 데이터 세트에 대해서는 이상적인 선택은 아닐 것이다. 그래서 3D 데이터를 사용할 때의 모델 데이터 단위가 2D가 아닌 3D단위를 사용하는 것이 좋다. 그래서 기존의 U-Net(2D)의 구조에서 3D로 바꾼 것이 해당 논문의 핵심이다.
요약
- 이전에 제시된 U-Net 2D연산을 3D로 확장시켰다.
- 3D U-Net은 3D volumes을 input으로 받으며, 3D convolutions, 3D max pooling, batch normalization(BN) 을 사용한다.
3D U-Net Architecture
Architecture 자체는 이전 U-Net에서 구조에서 크게 바뀌지 않았다.
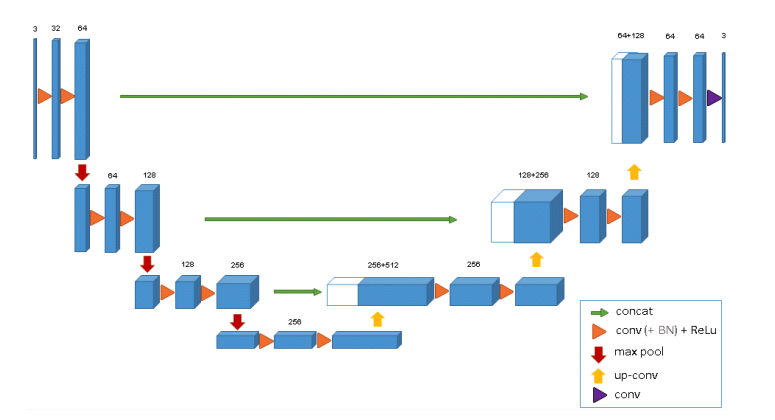
- 왼쪽 Layer에는 각 2개의 3x3x3 convolutions, ReLU, strides, max pooling 2x2x2,
- 오른쪽 Layer에는 각 2개의 2x2x2 up-convolutio, 3x3x3 convolutions, ReLu
- 마지막 Layer에서는 1x1x1 convolutions은 출력 채널 수를 labels 수인 3으로 줄임.
- 참고로 각 ReLu전에 batch normalization(BN) 사용.
그리고 그림을 보면, input shape이 output shape보다 작은데, 그 이유는 이미지를 한번에 넣지 않고 patch 단위로 넣었기 때문이다.
결과
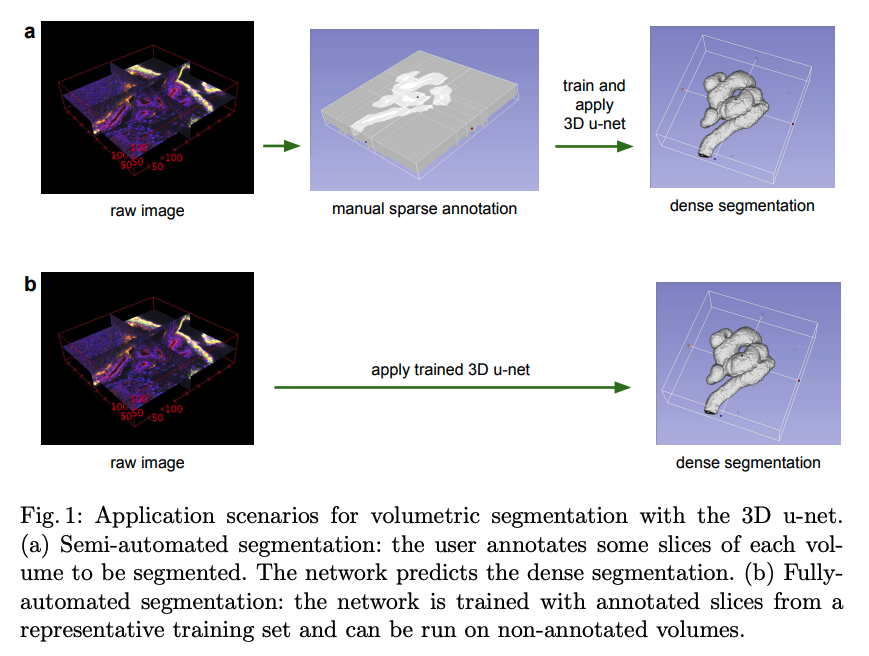
3D U-Net은 2가지 방법으로 사용 될 수 있다.
a) Semi-automated segmentation: 몇 개의 단면만 annotate이 달린 데이터를 가지고 dense segmentation을 예측.
b) Fullyautomated segmentation: annotate이 전부 달린 데이터를 학습 후, non-annotate 데이터 예측.
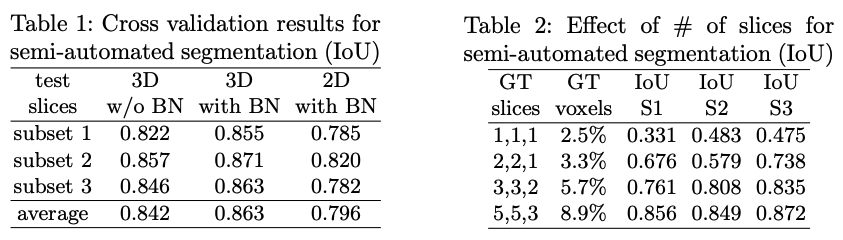
첫 번째 테이블을 보면 3개의 subset에 대해 3D+BN이 성능이 좋은 것을 알 수 있고, 두번째 테이블은 Semi-automated 학습에 사용되는 annotate 달린 단면(slices)의 개수가 많을수록 더 IoU가 높아진다.
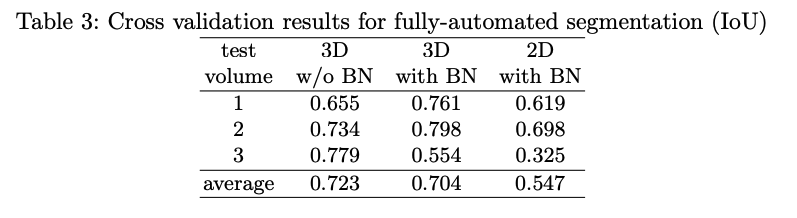
Fullyautomated segmentation에서도 2D+BN 보다 3D+BN를 사용하는 것이 좋다고 한다.