
Paper URL : https://arxiv.org/abs/1312.6229
OverFeat이 나오게 된 배경
OverFeat이 개발된 배경을 잠깐 살펴보자.
그 당시 컴퓨터 비전 분야의 상황과 기존 접근 방식의 한계를 살펴볼 필요가 있다. OverFeat논문은 2013년도에 발표된 논문인데, 이 시기는 이제 갓 딥러닝이 컴퓨터 비전 분야에서 주목받기 시작한 시점이다.
당시 많은 연구들이 이미지 분류, 객체 탐지, 위치 인식과 같은 특정 작업에 초점을 맞췄는데, 서로 다른 문제로 취급되었다. 그래서 각 작업은 별도의 모델, 알고리즘, 그리고 데이터셋에 의존했기 때문에 효율성과 일관성 측면에서 제한적이였다. 대표적으로 “R-CNN(2013) Rich feature hierarchies for accurate object detection and semantic segmentation Tech report (v5)” 의 논문이 이러한 경향을 대표하는 모델 중 하나이다.
이런 배경 속에서 OverFeat는 ConvNet을 사용하여 이미지 분류, 객체 탐지, 위치 추정 등 여러 작업을 동시에 처리하는 통합적인 프레임워크를 제시했다. 결론적으로 OverFeat는 단일모델로 여러 작업을 효과적으로 수행할 수 있는 새로운 방향을 제시하는데 중요한 역할을 했다.
OverFeat의 목표와 가설
- 목표 : OverFeat논문의 주요 목표는 컨볼루션 네트워크(ConvNet)을 훈련시켜 이미지 분류, 객체 탐지, 위치 추정 이 주요 3가지 작업을 통합적으로 처리하는 새로운 방법을 제시하는 것이다. 핵심은 하나의 ConvNet을 이용하여 다양한 작업을 동시에 수행하고 각 작업에 대한 정확도를 향상시키는 것에 있다.
- 가설 : OverFeat 논문의 가설은 “단일 ConvNet을 활용하여 이미지 내에서 다양한 위치와 스케일에 대해 객체를 효과적으로 분류, 위치 추정 및 탐지할 수 있다”는 것이다. 이 가설은 bounding box를 통합함으로써, 복잡한 훈련 절차나 배경 샘플에 의존하지 않고도 높은 정확도의 탐지가 가능하다고 제안하는 것이다. 결과적으로 ConvNet이 다양한 작업을 동시에 수행할 수 있는 강력한 표현력을 가지고 있음을 시사하며, 이를 통해 효율성과 성능을 동시에 향상시킬 수 있다는 가정에 기초하고 있다.
OverFeat의 특징
OverFeat의 특징으로는 Multi Scale, Spatial Outputs, ConvNets Sliding Window Efficiency, Offset Max Pooling 이렇게 4가지가 있다고 보면 된다.
1. Multi Scale

OverFeat모델에 입력되는 이미지가 하나의 고정된 크기가 아니라, 여러 가지 크기로 변환되어 입력된다. 이미지를 피라미드 형태로 변환하여 다양한 스케일의 이미지를 생성하며, Multi scale 방식을 사용하는 이유는 이미지 내 존재하는 다양한 크기의 객체보다 쉽게 포착하는 것이 가능해지기 때문이다. (다양한 크기와 해상도를 가지게 됨)
이 당시 OverFeat모델은 fc layer를 conv layer로 대체한 부분에 대해서는 놀랍지 않을 수가 없었는데, OverFeat이 등장하기 전에는 대부분의 CNN 모델들이 고정된 크기를 받았으며, OverFeat는 이러한 제한을 극복하기 위해 Multi-Scale 방식과 fc layer를 conv layer로 대체한거였다.
2. Spatial Ouput
- Non- Spatial : 이미지 전체에 대한 정보를 압축하거나 요약하는 경우, 이는 non-spatial output이며, 일반적으로 1X1 크기의 출력이 이에 해당하지만, 그 출력이 이미지 전체를 대표하는 정보를 담고 있는지가 중요함.
- Spatial Output : 여러 개의 공간적 위치에서 도출된 정보를 포함하고, 원본 이미지의 특정 부분에 대한 정보를 유지하고 있으며, 다양한 Output Map을 산출함.
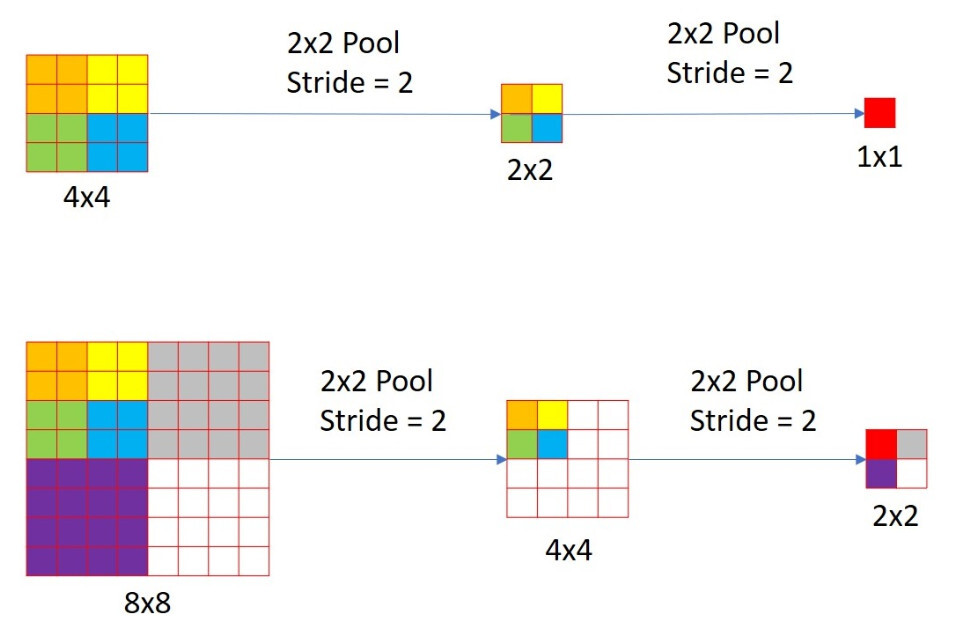
- Pooling Layer : 다양한 크기의 이미지가 2x2 pooling (stride=2) layer를 거치면 크기가 줄어들며, 각 이미지는 서로 다른 output을 산출한다.
- Non-Spatial vs. Spatial Output : 4x4 이미지가 pooling을 거치면 1x1 크기의 output map이 생성하는데, 이 output이 전체 이미지에 대한 정보를 압축하고 있다면, 그것은 non-spatial output라고 할 수 있다.
- Receptive Field : 1x1 크기의 픽셀이 나타내는 범위를 receptive field라고 한다. 해당 픽셀이 원본 이미지의 어느 부분을 대표하는지를 나타낸다.
- Spatial Output의 의미 : Spatial output은 원본 이미지의 특정 receptive field에 대한 정보를 인코딩하고, 각 요소가 이미지의 특정 영역에 대한 정보를 담고 있음을 의미한다.
3. ConvNets Sliding Window Efficiency
fc layer를 conv layer로 대체함으로써 sliding window와 같은 효과를 보다 효율적으로 구현하였다. 기존의 슬라이딩 윈도우 방식은 큰 이미지에서 사용하기에는 계산량이 매우 많기 때문에 CNN에서 가중치를 공유하여 연산량을 줄이는 방식을 제안했다.(conv layer에서 conv filter를 적용하는 과정에서 자연스레 겹치는 영역끼리 연산을 공유)
4. Offset Max Pooling
일반적인 Max Pooling과 유사하지만 위치 정보를 보전하기 위한 목적으로 추가하게 된다. Max Pooling은 feature map에서 가장 큰 값을 선택하여 출력하는 연산이지만, 위치 정보가 손실되는 문제가 있다. offset max pooling은 max pooling과 함께 이전 레이어의 위치 정보를 고려하여 최댓값의 위치를 반환한다.
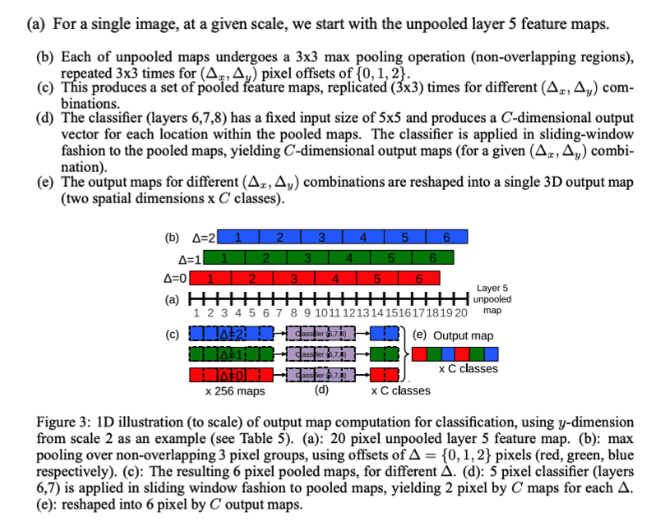
- Feature extractor의 마지막 pooling layer에 {0,1,2} 조합에 따라 총 9회 3x3 max pooling을 진행함
- 그래서 하나의 feature map에서 offsef max pooling을 하게 되면 총 9개의 featrue map이 출력 됨
- Spatial Output의 각 Pixel값이 Pooling시 원본 이미지의 어떤 receotive field에 해당되는지 파악함
OverFeat Model
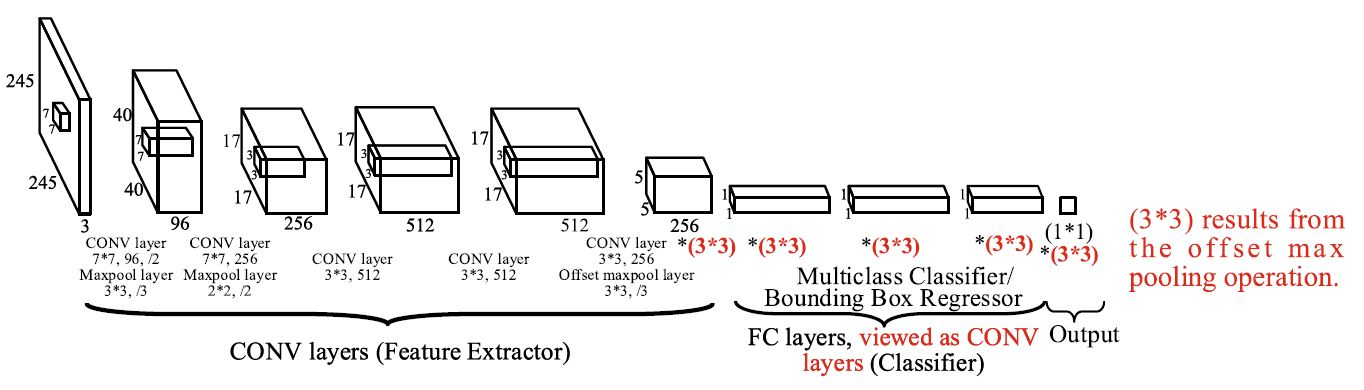
OverFeat은 위 그림과 같이 feature extractor로는 AlexNet 과 비슷한 구조를 사용하였고 이후 FC layer 대신 1x1 Conv network을 사용하여 다양한 input이 통과가능하도록 하였으며 classifier와 bbox regressor는 weight를 공유하여 Class과 BBox를 함께 training하고 예측가능하도록 구성했다.