
H사 신문사 웹스크롤링 하기-1(기사 제목)
워드 클라우드나 특정 데이터를 수집하기 위해 자주 사용되는 웹 스크롤링에 대해 한번 알아보겠습니다. 보통 웹 스크롤링 할때는 a태그에 있는 것을 긁어서 사용합니다. 저는 오늘 특정 신문사에서 기사를 긁어오는 것을 한번 해보겠습니다.
H사 웹 스크롤링 (기사 제목만 스크롤링)
신문사 홈페이지로 들어가서 찾고자 하는 것을 검색한 후 url을 가져오겠습니다.

여기서 알아야 할 점은 주소가 위 그림처럼 뜨지만, 주소를 메모장에 복붙하면 아래처럼 암호화 된 주소가 보여집니다. 그렇기 때문에 직접 URL를 건들어서 웹 스크롤링을 하기는 힘들다는 점을 알아두셔야합니다. 이제 여기서 우리가 해야 댈것은 페이지 번호를 확인하고 나서 for문을 돌려서 웹 스크롤링 할 예정입니다. 우선 F12를 눌러 기사 제목을 클릭해서 기사 제목을 확인해보겠습니다.
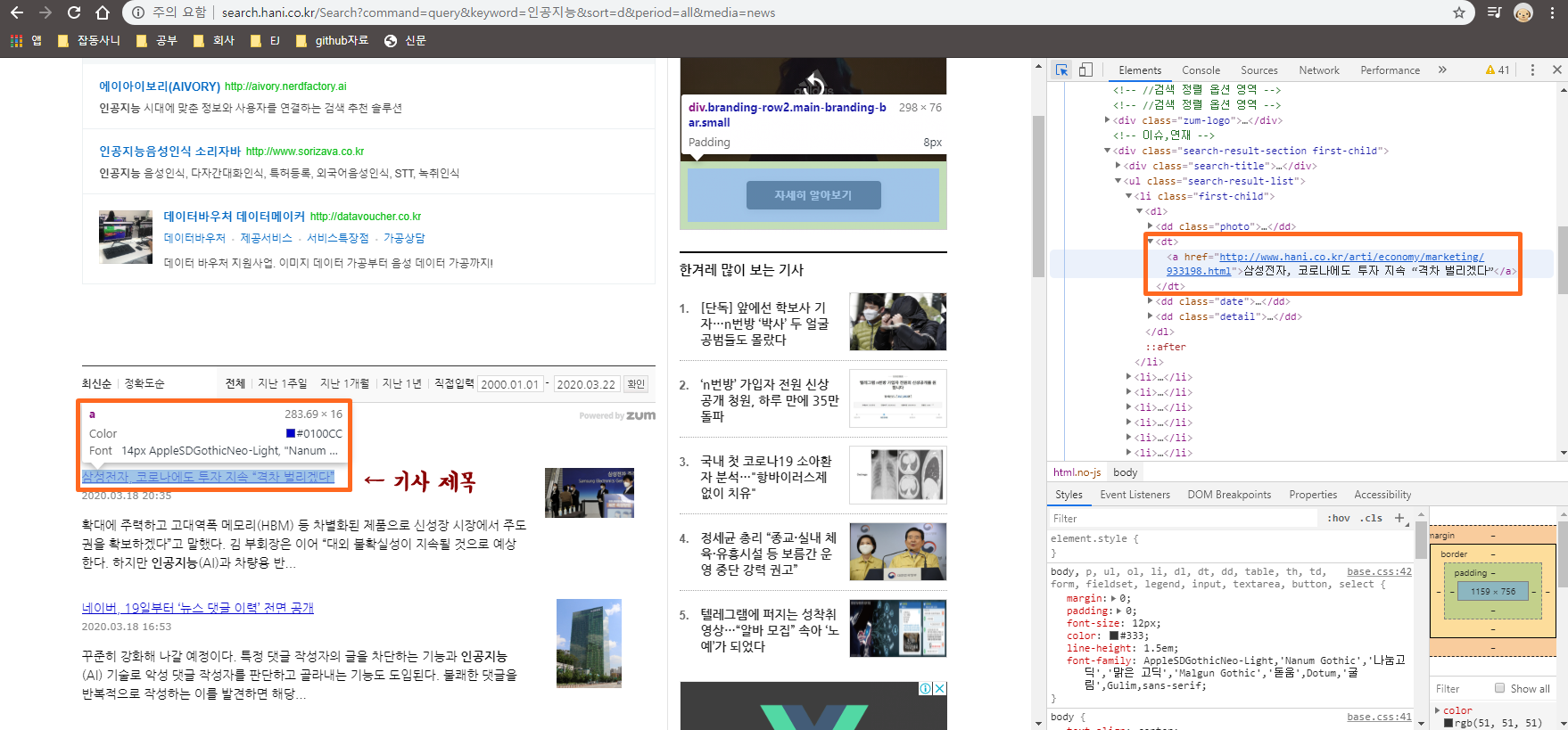
F12를 누른 후 ctrl+ shift+c를 누른 후 기사 제목을 클릭하고 dt 태그 밑에 있는 a태그에서 링크와 기사 제목이 있는지를 확인합니다. 우리는 기사 제목을 스크롤링 해야하므로 a태그를 스크롤링해야합니다.
확인했으면 이제 페이지 번호를 확인하기 위해서 다음 페이지로 넘어갑니다.
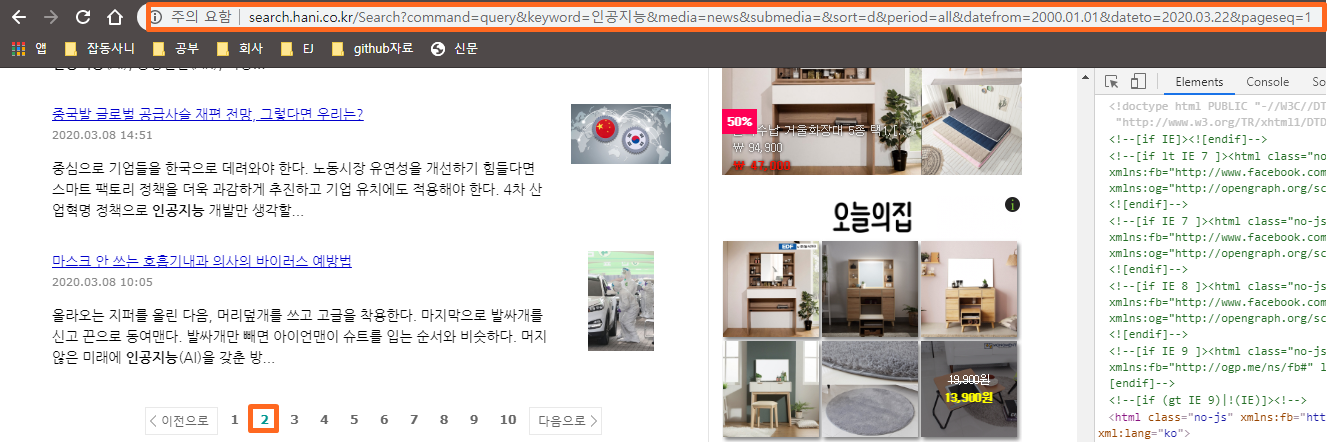
주소를 보면 pageseq 라는 것이 생기면서 URL주소가 바뀌는 것을 확인할 수 있습니다. 그럼 이제 준비는 끝났습니다. 페이지 번호가 들어간 URL과 기사 제목이 어디에 위치 했는지를 확인했으니 웹 스크롤링을 할수 있겠네요.
import urllib.request
from bs4 import BeautifulSoup # 웹 스크롤링을 위한 모듈
def fetch_list_url():
for i in range(100):
list_url = "http://search.hani.co.kr/Search?command=query&keyword=%EC%9D%B8%EA%B3%B5%EC%A7%80%EB%8A%A5&media=news&submedia=&sort=d&period=all&datefrom=2000.01.01&dateto=2020.03.22&pageseq="+str(i)
url = urllib.request.Request(list_url)
res = urllib.request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup(res, "html.parser")
for link in soup.find_all('dt'): # dt 태그 밑에 있는
for i in link: # a 태그를 가져오기
print(i.get('href')) # 기사 URL
print(i.get_text('href')) # 기사 제목
fetch_list_url()
웹 스크롤링이 잘되는 것을 확인할 수있습니다.
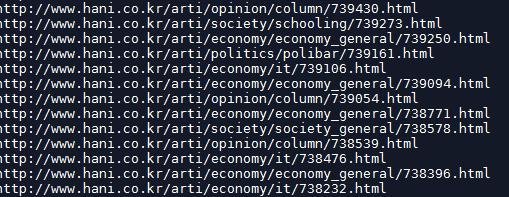
다음 포스팅에서는 신문사 기사 내용도 스크롤링하고 저장하는 것을 해보겠습니다.