
H사 신문사 웹스크롤링 하기-2(기사 내용)
지난 포스팅에서 기사 제목만을 스크롤링하는 것을 했는데, 이번에는 조금 더 나아가서 기사 내용까지 스크롤링해보도록 하겠습니다.
H사 웹 스크롤링 (기사 내용 스크롤링)
기사 내용을 스크롤링하기 위해 기사를 클릭 후 저번과 마찬가지로 F12를 눌러 기사 내용을 클릭합니다.
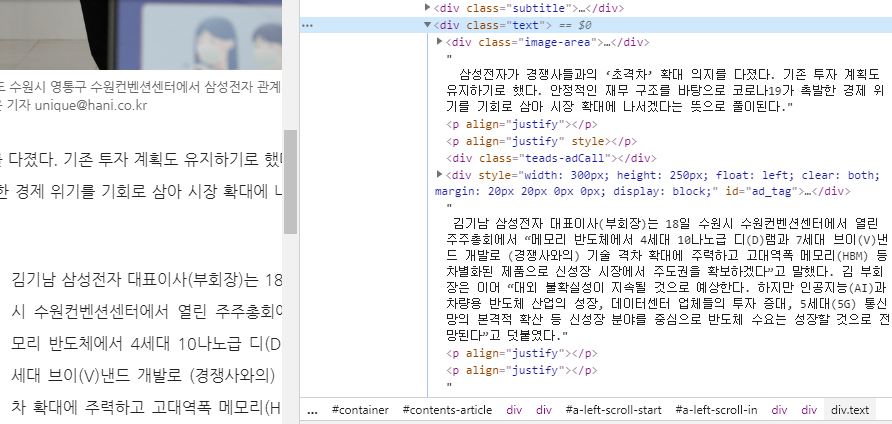
그럼 기사 내용이 div 태그에 text 클래스에 기사 내용이 있음을 확인할 수 있습니다. 여기서 기사 내용만을 클릭하면 언제 올라온 기사인지 모르니 기사 날짜도 함께 스크롤링합니다. 기사 날짜는 p 태그에 data-time 클래스가 있습니다.
import urllib.request
from bs4 import BeautifulSoup
def fetch_list_url():
# 현재 기사 URL
list_url = "http://www.hani.co.kr/arti/economy/marketing/933198.html
url = urllib.request.Request(list_url)
res = urllib.request.urlopen(url).read().decode("utf-8")
#print(res) # 위의 두가지 작업을 거치면 위의 url 의 html 문서를 res 변수에 담을수 있게 된다.
soup = BeautifulSoup(res, "html.parser")
params1 =[]
params2 =[]
for link1,link2 in zip(soup.find_all('p', class_="date-time"),soup.find_all('div', class_="text")):
params1.append( link1.get_text() )
params2.append( link2.get_text() )
for i1,i2 in zip(params1,params2):
print(i1.strip(),end=' ')
print(i2.strip())
fetch_list_url()
그럼 여기서 현재 기사 URL만 스크롤링하지 않고 아래의 두가지 조건을 만족하는 웹 스크롤링을 작성해보겠습니다.
- 1. 인공지능으로 검색한 페이지의 기사 URL을 가져오는 코드
- 2. 그 상세 URL로 기사 날짜와 기사 내용을 검색하는 코드
저번 포스팅에서 사용한 코드와 오늘 작성한 코드를 합치면 간단하게 만들 수 있습니다.
import urllib.request
from bs4 import BeautifulSoup
def fetch_list_url():
params=[]
for i in range(50):
list_url = "http://search.hani.co.kr/Search?command=query&keyword=%EC%9D%B8%EA%B3%B5%EC%A7%80%EB%8A%A5&media=news&submedia=&sort=d&period=all&datefrom=2000.01.01&dateto=2020.03.22&pageseq="+str(i)
url = urllib.request.Request(list_url)
res = urllib.request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup(res,"html.parser")
for link in soup.find_all('dt'):
for i in link:
params.append(i.get('href'))
return params
def fetch_list_url2():
list_url = fetch_list_url() # 리스트를 한번에 받아오기
for i in range(len(list_url)):
url = urllib.request.Request(list_url[i])
res = urllib.request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup(res, "html.parser")
params1 =[]
params2 =[]
for link1,link2 in zip(soup.find_all('p', class_="date-time"),soup.find_all('div', class_="text")):
params1.append( link1.get_text() )
params2.append( link2.get_text() )
for i1,i2 in zip(params1,params2):
print(i1.strip(),end=' ')
print(i2.strip())
print(fetch_list_url2())
추가로 여기서 스크롤링한 기사를 메모장에 저장하고 난 최종 코드는 아래와 같이 작성할 수 있습니다.
import urllib.request
from bs4 import BeautifulSoup
def fetch_list_url():
txt_list = []
for i in range(20):
list_url = "http://search.hani.co.kr/Search?command=query&keyword=%EC%9D%B8%EA%B3%B5%EC%A7%80%EB%8A%A5&media=news&submedia=&sort=d&period=all&datefrom=2000.01.01&dateto=2020.03.22&pageseq="+str(i)
url = urllib.request.Request(list_url)
res = urllib.request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup(res, "html.parser")
article_title_url = soup.find_all('dt')
for link in article_title_url:
for i in link:
article_list_url = i.get('href')
article_url = urllib.request.Request(article_list_url)
article_res = urllib.request.urlopen(article_url).read().decode("utf-8")
soup = BeautifulSoup(article_res, "html.parser")
article_content = soup.find_all('div', class_="text")
article_date = soup.find_all('p', class_="date-time")
for i, j in zip(article_date,article_content):
txt_list.append(i.get_text(' ', strip = True)+' ')
txt_list.append(j.get_text(' ', strip = True).replace('\n',' ')+'\n')
return txt_list
f = open('data.txt','w',encoding="UTF-8")
f.writelines(fetch_list_url())
f.close()
다음 포스팅에서는 검색어를 입력하면 자동으로 스크롤링하게 해보겠습니다.