
J사 신문사 웹스크롤링 하기
저번에 H사 신문사를 웹 스크롤링해봤습니다. 신문사마다 주소가 다르기 때문에 이번에는 J사 주소를 가지고 와서 저번이랑 똑같이 웹 스크롤링을 해보도록 하겠습니다.
J사 웹스크롤링
우선 중앙일보 신문사 링크를 가져와 보겠습니다.
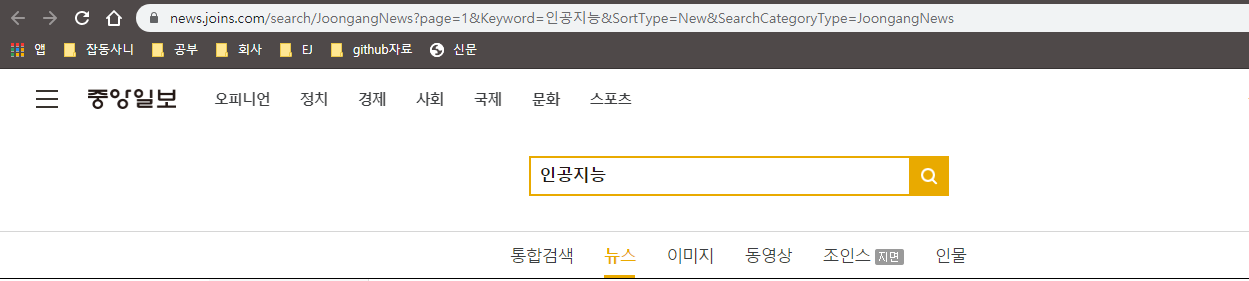
저번과 마찬가지로 메모장에 복붙하면 암호화 된 주소 를 확인할 수있습니다.
import urllib.request
from bs4 import BeautifulSoup
search_text = input("검색어를 입력하세요 : ").encode("utf-8")
search_text = str(search_text)[2:-1].replace('\\x', '%')
list_url = "hhttp://search.joins.com/JoongangNews?page=2&Keyword=" + search_text + "&SortType=New&SearchCategoryType=JoongangNews"
여기서 저번과 마찬가지로 페이지 번호를 확인하여 for을 통해 스크롤링하겠습니다.
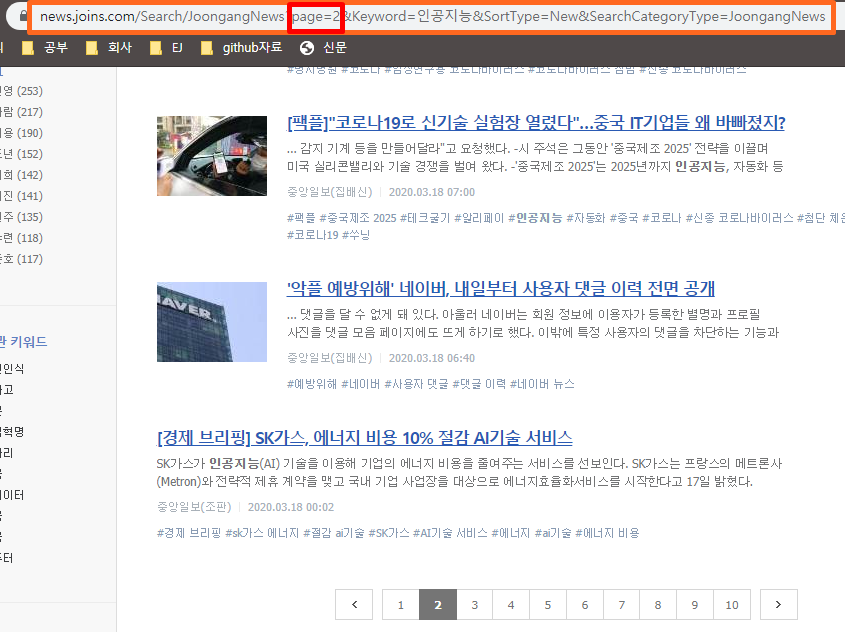
def fetch_list_url():
params = []
for i in range(2):
list_url = "https://news.joins.com/Search/JoongangNews?page=" + str(i+1) + "&Keyword=%EC%9D%B8%EA%B3%B5%EC%A7%80%EB%8A%A5&SortType=New&SearchCategoryType=JoongangNews"
url = urllib.request.Request(list_url)
res = urllib.request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup(res, "html.parser")
for link in soup.find_all(class_="headline mg"):
for i in link:
params.append(i.get('href')) # 신문자 URL
return params
최종적으로 작성하면 아래와 같이 작성 할 수 있겠습니다.
import urllib.request
from bs4 import BeautifulSoup
search_text = input("검색어를 입력하세요 : ").encode("utf-8")
search_text = str(search_text)[2:-1].replace('\\x', '%')
list_url = "hhttp://search.joins.com/JoongangNews?page=2&Keyword=" + search_text + "&SortType=New&SearchCategoryType=JoongangNews"
def fetch_list_url():
params = []
for i in range(2):
list_url = "https://news.joins.com/Search/JoongangNews?page=" + str(i+1) + "&Keyword=%EC%9D%B8%EA%B3%B5%EC%A7%80%EB%8A%A5&SortType=New&SearchCategoryType=JoongangNews"
url = urllib.request.Request(list_url)
res = urllib.request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup(res, "html.parser")
for link in soup.find_all(class_="headline mg"):
for i in link:
params.append(i.get('href')) # 신문자 URL
return params
def fetch_list_url2():
params3 = []
list_url = fetch_list_url()
for i in range(len(list_url)):
url = urllib.request.Request(list_url[i])
res = urllib.request.urlopen(url).read().decode("utf-8")
soup = BeautifulSoup(res, "html.parser")
params1 = []
params2 = []
for link1, link2 in zip(soup.find_all('div', class_="byline"), soup.find_all('div', id="article_body")):
params1.append(link1.get_text())
params2.append(link2.get_text())
for i1, i2 in zip(params1, params2):
params3.append(i1.strip())
params3.append(i2.strip())
return params3
f = open('ydata3.txt', 'w', encoding='UTF-8')
f.writelines(fetch_list_url2())
f.close()