
저번에 중앙일보와 한계례 신문사를 저번에 웹 스크롤링하는 것을 했습니다. 두번정도 해보니까 이제 슬슬 감이 잡히지 않던가요 ? 링크랑 기사내용 태그만 확인하면 스크롤링 되는 것을 확인 했으니, 이번엔 그냥 전체 신문사에서 선택해서 스크롤링하는 스크립트를 짜볼까합니다.
웹 스크롤링 함수 구현
우선 자신의 컴퓨터 user-agent를 확인해야합니다. 여기를 눌러 자신의 agent를 꼭 확인합니다.
우리는 메인 함수와 서브 함수 두가지를 우선 만들어야 합니다. 메인 함수는 스크롤링한 text를 리턴하는 함수를 만들고, 서브 함수는 두 가지 정도를 만들려고 합니다. 서브 함수는 기사 상세 url과 기사 text를 리스트를 append시키는 함수, 그리고 url를 입력받아 html로 변환하고 beautiful soup에서 사용할수 있도록 설정하는 함수를 만들겠습니다.
우선 서브 함수로 url를 받아서 html로 변화하는 함수를 만들겠습니다.
import urllib.request as rq
from bs4 import BeautifulSoup
def start(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36',}
url = rq.Request(url, headers = headers)
res = rq.urlopen(url).read()
return BeautifulSoup(res, "html.parser")
그리고 기사 url과 기사 text를 리스트에 담는 함수를 작성합니다.
def news_fetch(url, tag):
soup = start(url)
for link in soup.select(tag[1]):
result.append(link.get_text())
그리고 메인 함수인 스크롤링한 text를 리턴하는 함수를 작성합니다.
def fetch_list_url(url, tag):
global result
soup = start(url)
for link in soup.select(tag[0]):
result.append(link.get_text())
print('link =' ,link['href'], link.get_text())
news_fetch(link['href'], tag)
이제 가장 중요한 url링크와 기사 내용을 스크롤링해야 할 태그 부분을 가져옵니다.
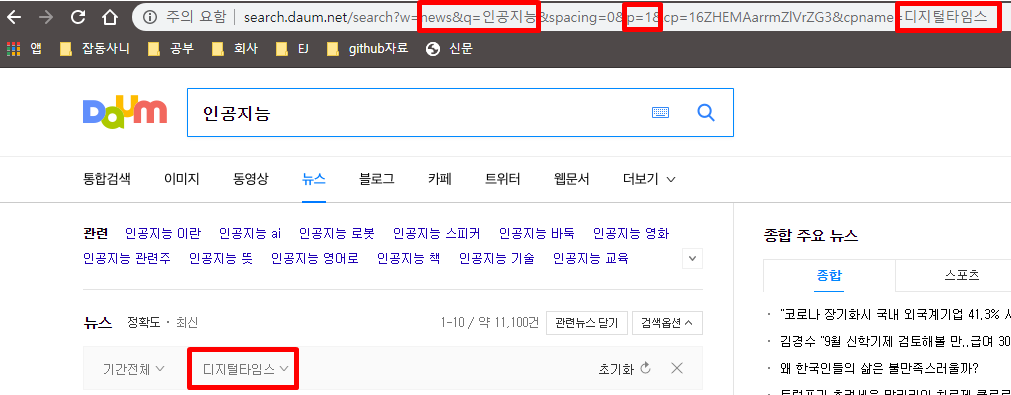
result = []
url_list = ['http://search.daum.net/search?w=news&q={search}&spacing=0&p={page}&cp=16ZHEMAarrmZlVrZG3&cpname=%EB%94%94%EC%A7%80%ED%84%B8%ED%83%80%EC%9E%84%EC%8A%A4', ["#clusterResultUL > li > div.wrap_cont > div > div > a", "#resizeContents > div"]]

여기서 이제 주소 끝 부분에 ‘디지털 타임즈’가 아니라 각종 신문사를 넣어 링크를 여러개 만들어 전체 신문사를 스크롤링 스크립트를 작성하려고 합니다.
전체 신문사 기사 스크롤링
신문사를 선택해서 스크롤링 하는 최종 코드는 아래와 같습니다.
import urllib.request as rq
from bs4 import BeautifulSoup
from wordcloud import WordCloud, STOPWORDS
import matplotlib.pyplot as plt
from os import path
import re
def start(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36',}
url = rq.Request(url, headers = headers)
res = rq.urlopen(url).read()
return BeautifulSoup(res, "html.parser")
def fetch_list_url(url, tag):
global result
soup = start(url)
for link in soup.select(tag[0]):
result.append(link.get_text())
print('link =', link['href'], link.get_text())
news_fetch(link['href'], tag)
def news_fetch(url, tag):
soup = start(url)
for link in soup.select(tag[1]):
result.append(link.get_text())
result = []
search_text = str(input("검색어를 입력하세요 : ").encode("utf-8"))[2:-1].replace('\\x', '%')
def numbers_to_strings():
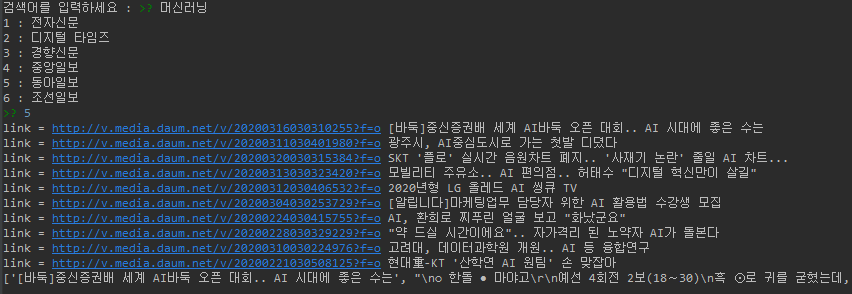
num = input('1 : 전자신문 \n2 : 디지털 타임즈 \n3 : 경향신문 \n4 : 중앙일보 \n5 : 동아일보 \n6 : 조선일보\n')
switcher = {
1: ['http://search.daum.net/search?w=news&q={search}&spacing=0&p={page}&cp=16yGc-mR1Rz5JT4-UZ&cpname=%EC%A0%84%EC%9E%90%EC%8B%A0%EB%AC%B8&DA=PGD', ["#clusterResultUL > li > div.wrap_cont > div > div > a", "#articleBody > p"]],
2: ['http://search.daum.net/search?w=news&q={search}&spacing=0&p={page}&cp=16ZHEMAarrmZlVrZG3&cpname=%EB%94%94%EC%A7%80%ED%84%B8%ED%83%80%EC%9E%84%EC%8A%A4', ["#clusterResultUL > li > div.wrap_cont > div > div > a", "#resizeContents > div"]],
3: ['http://search.daum.net/search?w=news&q={search}&spacing=0&p={page}&cp=16bfGN9mQcFhOx4F5l&cpname=%EA%B2%BD%ED%96%A5%EC%8B%A0%EB%AC%B8', ["#clusterResultUL > li > div.wrap_cont > div > div > a", "#container > div.main_container > div.art_cont > div.art_body > p"]],
4: ['http://search.daum.net/search?nil_suggest=btn&w=news&cluster=y&q={search}&cp=16nfco03BTHhdjCcTS&cpname=%EC%A4%91%EC%95%99%EC%9D%BC%EB%B3%B4&p={page}',["#clusterResultUL > li > div.wrap_cont > div.cont_inner > div > a " ,"#article_body"]],
5: ['http://search.daum.net/search?w=news&nil_search=btn&enc=utf8&cluster=y&cluster_page=1&q=AI&cp=16Et2OLVVtHab8gcjE&cpname={search}&DA=PGD&p={page}',["#clusterResultUL > li > div.wrap_cont > div.cont_inner > div > a " , "div.article_txt "]],
6: ['http://search.daum.net/search?w=news&nil_search=btn&enc=utf8&cluster=y&cluster_page=1&q=AI&cp=16EeZKAuilXKH5dzIt&cpname={search}&p={page}',["#clusterResultUL > li > div.wrap_cont > div.cont_inner > div > a ","div.par"]]
}
return switcher.get(int(num), "nothing")
url_list = numbers_to_strings()
for i in range(1, 2):
url, tag = url_list[0].format(search=search_text, page=i), url_list[1]
fetch_list_url(url, tag)
print(result)
f = open('data3.txt', 'w', encoding='UTF-8')
f.writelines(result)
f.close()
여기서 알아둬야 할 점은, 신문사 같은 경우는 웹 스크롤링하는 사람이 꽤 있다고 들어서 신문사들도 태그나 URL를 바꾸는 경우도 있다고 합니다. 그래서 현재 작성된 코드가 지금은 돌아가더라도 시간이 지난 뒤에는 안돌아갈 수 있으니 이 부분을 꼭 참고하셔서 작성하셔야합니다.