
오늘은 K-Nearest Neighbors(KNN)라는 알고리즘에 대해 알아보려고 한다. Knn 머신러닝을 공부하면 가장 쉽게 먼저 접하는 알고리즘 중 하나이다.
이번 포스팅에서는 Knn이 무엇인지, 필요한 이유에 대해 알아보자.
knn이란 무엇인가?
사회적인 관계를 관찰해본적인 있나요? 대략적으로 비슷한 사람끼리 모이는 성질이 있다고 한다. 그래서 비슷한 취향의 사람들끼리 모여서 동회회를 만들거나 비슷한 부류의 계층의 사람들끼리 친분을 맺기도 한다.
그렇다면 공간적은 관계를 관찰해볼까?
길을 지나다가 보면 가구점이 모여있는 상가지역이 따로 형성된 곳이 있다. 한약방이 밀집되어 있는 지역이나, 가구점, 음식점 등 밀집되어 있는 지역이 따로 모여 있는 경우가 많은 것을 우리는 길을 지나다가 느낄 수 있다.
이러한 특성을 가진 데이터를 겨낭해서 만들어진 알고리즘이 knn이다.
knn이 필요한 이유
유방암의 데이터를 가지고 있다고 가정을 했을때, 유방암의 종양의 크기에 대한 데이터(반지름, 둘레, 면적 등)만을 가지고 이 종양이 악성인지, 양성인지 예측할 수 있다. 그렇다면 환자에 대한 치료 스케줄에 큰 영향을 미칠 수 있다.
knn 분류 이해
knn은 어떤 라벨을 정의할 때, 그 데이터의 주변 반경 ε(입실론)안의 데이터들의 라벨들을 조사하여 다수결로 k개 이상이면 가장 많은 라벨로 정의 하는 것을 knn 분류라고 한다.
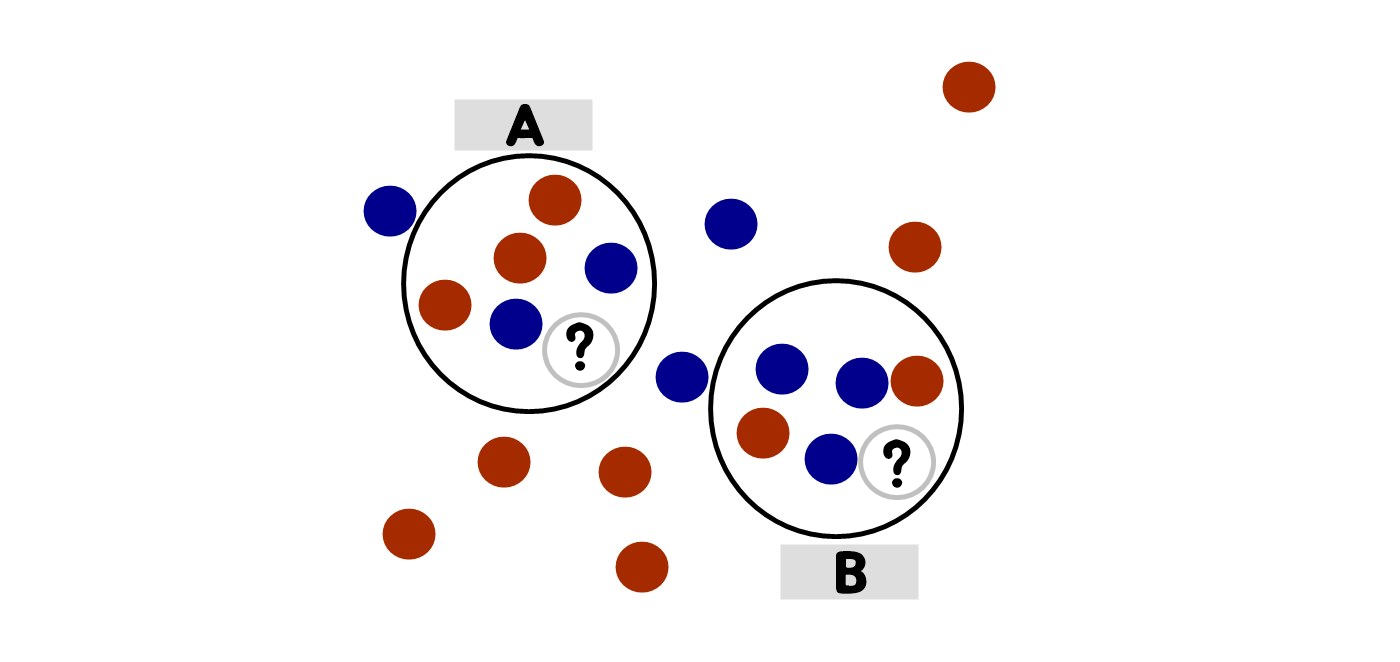
knn을 5로 잡았을 때를 가정으로 하면 위처럼 표시 할 수 있다. A에는 빨간색이 많았으므로 물음표안에는 빨간색이 들어가고, B에는 파란색이 들어간다. 어떠한 라벨을 정의할 때, 다수결로 k개 이상이면 가장 많은 라벨로 정의 하는 것을 knn 분류라고 한다.