K-Nearest Neighbors(Knn)을 이용하여 유방암 분류하기
오늘은 knn을 사용하여 유방암 분류를 해볼까합니다. 데이터는 데이터는 여기에서 볼 수 있으며 전체 코드 역시 GitHub에서 보실 수 있습니다. 원래 오늘 적절한 k값을 알아내는 것에 관려하여 포스팅을 할 예정이였으나, R에서 knn 관련 데이터 예제로 가장 많이 사용하는 것중에서 하나만 집고 넘어가는 것도 나쁘지 않고 해서 오늘은 유방암 데이터를 가지고 분류를 해보도록 하겠습니다.
DataSet
우선 데이터를 load 해보겠습니다.
wisc<-read.csv("wisc_bc_data.csv",stringsAsFactors=FALSE, header = F)
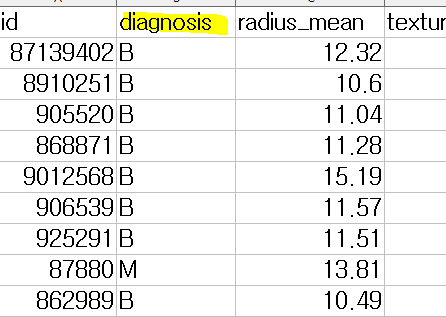
데이터에서 diagnosis는 라벨이며, B는 양성이고, M이 악성입니다. 전체 라벨에 대해 분포를 보면, 총 569명중에서 1/3이 악성이고 2/3이 양성임을 알 수 있습니다.
wbcd$diagnosis <-factor(wbcd$diagnosis, levels = c("B","M"),labels=c("Benign","maliganant"))
round(prop.table(table(wbcd$diagnosis)),1)*100
Normalize
저번에 만든 정규화 함수를 이용하여 정규화 작업을 하겠습니다.
normalize <- function(x){
return((x-min(x))/(max(x)-min(x)))}
wbcd_n <- as.data.frame(lapply(wbcd[,3:31], normalize))
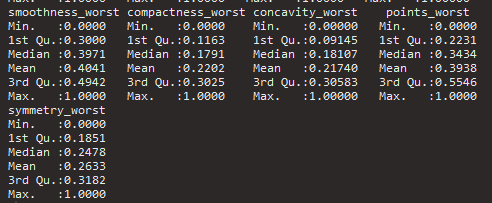
summary(wbcd_n) # 정규화가 잘 되었는지 확인
# 0 ~ 1 사이에 있는지 / min 과 max
그리고 전체 데이터에서 훈련 데이터와 학습 데이터를 나누는 작업을 하고 knn으로 돌려주겠습니다.
nrow(wbcd_n) # 건수를 확인하는 함수 .
wbcd_train <- wbcd_n[1:469,]
wbcd_test <- wbcd_n[470:569,]
wbcd_train_label <- wbcd[1:469,2]
wbcd_test_label <-wbcd[470:569,2]
Knn
knn을 아래와 같이 돌려줍니다.
library(class)
result1 <- knn(wbcd_train, wbcd_test, wbcd_train_label, k=21)
## 실제 라벨과 테스트 라벨과 비교를 해본다 .
data.frame(wbcd[470:569,2],result1)
모델의 정확도는 아래와 같이 구할 수 있습니다.
prop.table(table(ifelse(wbcd[470:569,2]==result1,"o",'x')))
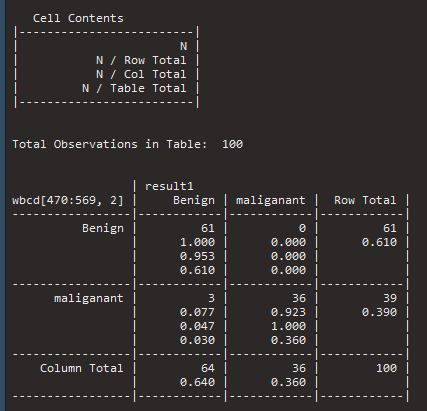
그럼 정확도가 대략 97%정도임을 알 수 있습니다. 여기서 그냥 끝내기는 조금 아쉬우니 이원 교차표를 그려서 자세하게 모델에 대해 보겠습니다.
CrossTable(x=wbcd[470:569,2], y=result1, prop.chisq = FALSE )
이원 교차표를 보면 악성인데, 양성으로 오진한 결과 때문에 정확도가 떨어짐을 알 수 있습니다.