K-Nearest Neighbors(Knn)적잘한 k값 알아내는 방법
오늘은 적절한 k값을 알아내는 방법에 대해 이야기 해보겠습니다. 여태껏 이 블로그에서 다양한 데이터를 사용하여 knn 분류를 해보았는데, 그때마다 k값을 다르게 하면 매번 값이 달라진다는 것을 어렴풋 다들 알고 계실꺼라 생각합니다. 그렇다면 적절한 k값을 찾기 위해서는 어떻게 해야댈까요 ? 오늘은 그 방법에 대해 알아보겠습니다. 마찬가지로 데이터는 데이터는 여기에서 볼 수 있으며 전체 코드 역시 GitHub에서 보실 수 있습니다.
DataSet
이번 데이터는 부도 데이터이며, load 후에 결측값과 공백값을 제거하겠습니다.
HMEQ <- read.csv('DT_HMEQ.csv', stringsAsFactors = F)
HMEQ <- HMEQ[HMEQ$REASON != "" & HMEQ$JOB != "",] # 공백값 제거
HMEQ <- na.omit(HMEQ) # 결측값 제거
nrow(HMEQ)
knn
명록형 변수인 REASON, JOB을 더미코딩하겠습니다.
HMEQ$REASON <- ifelse(HMEQ$REASON == 'HomeImp',0,1)
HMEQ$JOB0 <- ifelse(HMEQ$JOB == 'Other', 1,0)
HMEQ$JOB1 <- ifelse(HMEQ$JOB == 'Office', 1,0)
HMEQ$JOB2 <- ifelse(HMEQ$JOB == 'Mgr', 1,0)
HMEQ$JOB3 <- ifelse(HMEQ$JOB == 'ProfExe', 1,0)
HMEQ$JOB4 <- ifelse(HMEQ$JOB == 'Sales', 1,0)
HMEQ <- cbind(HMEQ[1:5],HMEQ[7:18]) # 사용할 변수로만 데이터 다시 생성
그리고 라벨을 제외한 모든 컬럼을 정규화, 랜덤 샘플링, 데이터 프레임을 나눠줍니다.
HMEQ[2:17] <- as.data.frame(lapply(HMEQ[2:17], scale))
# 랜덤 샘플링 (8:2)
set.seed(12345)
HMEQ_rand <- HMEQ[order(runif(3364)), ]
# 데이터 프레임 나누기
train <- HMEQ_rand[1:2691, 2:17]
test <- HMEQ_rand[2692:3364, 2:17]
train_labels <- HMEQ_rand[1:2691, 1]
test_labels <- HMEQ_rand[2692:3364, 1]
그리고 knn을 실행합니다.
library(class)
library(gmodels)
test_pred <- knn(train, test, cl = train_labels, k=3)
res <- CrossTable(x = test_labels, y = test_pred, prop.chisq=FALSE)
accuracy <- sum(diag(res$t)/nrow(test))
적절한 k값 찾기
여기까지는 지금까지 계속 했던 knn과 다를것이 없지만, 적절한 k값은 지금부터 찾을 예정입니다. 우선 적잘한 k을 위해 변수를 생성합니다.
kvalue <- NULL
accuracy_k <- NULL
그리고 for loop를 사용하여 k값에 따른 정확도를 구합니다.
# for loop를 사용하여 k값에 따른 정확도 구하기
for(kk in c(1:100)){
knn_k <- knn(train, test, cl = train_labels, k = kk)
kvalue <- c(kvalue, kk)
res <- CrossTable(x = test_labels, y = knn_k, prop.chisq=FALSE)
# 분류 정확도 계산하기
accuracy <- sum(diag(res$t)/nrow(test))
accuracy_k <- c(accuracy_k, accuracy)
}
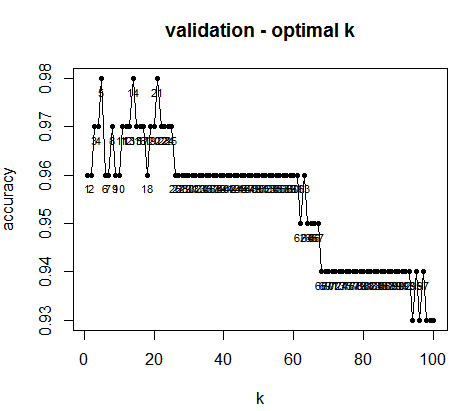
그리고 k값에 따른 분류정확도를 생성하고, 그래프를 그려 시각화합니다.
# k값에 따른 분류정확도 생성
valid_k <- data.frame(k = kvalue, accuracy = accuracy_k)
# k에 따른 분류 정확도 그래프 그리기
plot(formula = accuracy ~ k,
data = valid_k,
type = "o",
pch = 20,
main = "validation - optimal k")
# 그래프에 k 라벨링 하기
with(valid_k, text(accuracy ~ k, labels = rownames(valid_k), pos = 1, cex = 0.7))
적절한 k값 찾기 2
그렇다면 저번 포스팅때 했던 유방암 데이터에 맞는 적절한 k값이 무엇인지 한번 구해보겠습니다.
kvalue <- NULL
accuracy_k <- NULL
for(kk in c(1:100)) {
knn_k <- knn(wbcd_train, wbcd_test, cl=wbcd_train_label, k=kk)
kvalue <- c(kvalue, kk)
res <- CrossTable(x=wbcd[470:569,2], y=knn_k, prop.chisq=F)
accuracy <- sum(diag(res$t)/nrow(wbcd_test))
accuracy_k <- c(accuracy_k, accuracy)
}
valid_k <- data.frame(k = kvalue, accuracy = accuracy_k)
plot(formula = accuracy ~ k,
data = valid_k,
type = "o",
pch = 20,
main = "validation - optimal k")
with(valid_k, text(accuracy ~ k, labels = rownames(valid_k), pos = 1, cex = 0.7))
여기서 알아야 할 점은 정확도 그래프 수치가 알고리즘을 돌릴 때마다 매번 바뀌므로 공통적으로 정확도가 높은 k값을 찾아아합니다.