
실제 심장질환 데이터를 분석하여 심장질환에 있어 가장 영향력이 큰 변수를 찾아보도록 하겠습니다. 데이터 상세 설명은 여기에서 볼 수 있으며, 데이터는 여기에서 다운 받을 수 있습니다. 그리고 코드는 여기 GitHub에서 확인 할 수 있습니다.
DataSet
데이터 셋 설명은 아래와 같습니다.
- trestbps ( resting blood pressure ) : 안정시 혈압(수축기 고혈압)
- chol (serum cholesterol) : 고지혈증
- fbs ( fasting blood sugar larger 120mg/dl (1 true) ) : 당뇨가 있냐 없냐 ? 보통 126을 기준으로 126이상이면 당뇨인데 여기 데이터셋은 120을 기준으로 한다.
- restecg (resting electroc. result (1 anomality)) : 몸의 소금기 상태. 전해질( 나트륨, 칼륨, 염소 ) 중에 몇개가 보이는가 ? 보통 나트륨, 칼륨이 많다.
- thalach (maximum heart rate achieved ) : 최대 심박수(60~80 이 정상이고 100회 이상이면 빠르다)
- exang (exercise induced angina (1 yes) ) : 뛸때 가슴통증을 유발하는가 (협심증의 판단의 기준)
- oldpeak (ST depression induc) : 운동부하로 ST(아래 심전도에 보이는선) 이 기준선 아래로 떨어지는지
- slope (slope of peak exercise ST ) : ST 경사각도가 올라가는 경우 심근경색이 있을때 경사가 기울어진다.
- ca (number of major vessel ) : 심장으로 들어가는 3개의 혈관이 막혔는지 ( 데이터 셋에서 1개가 막혔는지 2개가 막혔는지 표시됨)
- thal (no explanation provided, but probably thalassemia
(3 normal; 6 fixed defect; 7 reversable defect) : 살라세미아는 지중해 지역에 사는 사람들에게 발생하는 빈혈관련 병으로 우리나라에서는 거의 환자가 없어 희귀병으로 보고 있다.
( 데이터 셋 : 3은 정상이고 6은 해결할수 없으며 7은 해결가능한 상태다) - num ( diagnosis of heart disease (angiographic disease status) ) : 이 데이터 셋의 라벨로 심장질환의 갯수를 나타낸다.
이 데이터에서 대부분 피검사와 운동검사를 통해 얻어진 데이터이고, 정보획득량은 thal(지중해성 빈혈)이 가장 높으나 우라나라에서는 희귀병이므로 이 외의 요소인 이 외의 요소인 가슴통증과 oldpeak(운동부하의 ST 선) 등이 심장질환 판단에 중요한 변수가 되겠습니다.
정보획득량
우선 예쁜 시각화를 그리기 위해서 시각화 그래프 패키지를 설치하겠습니다
install.packages("rpart")
install.packages("rattle")
install.packages("FSelector")
library(rattle)
library(rpart.plot)
library(FSelector)
시각화 그래프 깔면서 엔트로피 구하는 패키지도 깔았기 때문에 간단히 정보획득량 구해보겠습니다.
hr<-read.csv("Heart.csv", header = T)
head(hr)
a<-information.gain(AHD~., hr[,-1])
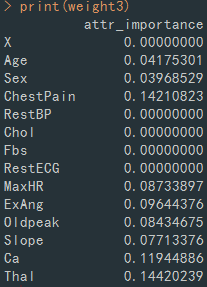
의사 결정나무(Decision Tree)
위에서 깐 패키지를 이용하면 예쁜 의사 결정나무 트리를 구할 수 있습니다.
tree <- rpart(AHD~.,data=hr[,-1], control=rpart.control(minsplit=2))
fancyRpartPlot(tree)
아래와 같은 그래프를 볼 수 있는데, 여기서 이 데이터 분석에 대한 결과를 설명한다고 할때, 어떻게 할 수 있을까 ?
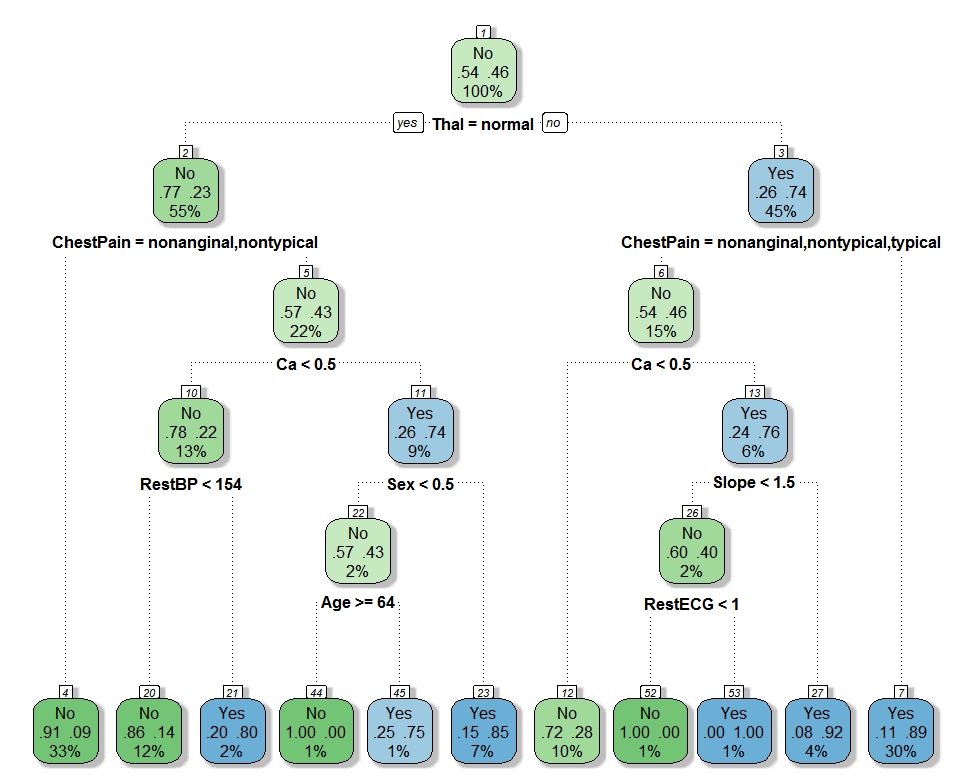
데이터 분석에 대한 결과
데이터 분석은 분석 결과를 잘 설명하는 것도 중요합니다. 그렇기 때문에 데이터를 시각화나 분석을 한 후에, 사람들에게 잘 설명할 수 있도록 글을 쓰는 연습을 충분히 해야합니다.
그렇다면 심장질환 데이터를 이용하여 정보획득량과 의사 결정나무를 시각화했는데, 이 결과를 바탕으로 환자나, 결정나무에 대해 상세 설명을 해야 한다면 어떻게 할까요 ? 아마 아래와 같이 분석 결과를 쓸 수 있을 것 같습니다.
심장 질환과 관련하여 76개의 변수를 관찰하였으나 의미 있는 변수는 14가지 정도로 추릴 수 있습니다. 이 14개의 변수는 각각 age(나이), sex(성별), cp(가슴 통증), trestbps(혈압), chol(콜레스트롤), fbs(혈중 당 농도), restecg(체내 전해질 상태), thalach(최대 심박수), exang(운동 시 가슴 통증), oldpeak (운동부하 시 심전도 상태), ca(심장 혈관의 원활함), thal(지중해성 빈혈), num(심장 질환과 관련한 진단 개수)이다. 이중 주목할 만한 변수는 thal, 즉 지중해성 빈혈이다. 이 변수가 다른 변수와는 달리 보편적이지 않은 이유는 이 데이터가 스위스, 캘리포니아의 롱 비치, 부다페스트 등 해안 연안에 위치한 기관에서 수집한 데이터이기 때문이다. 이 때문에 데이터에 바다 근처 환자들이라는 특징이 주어진다.
심장 질환의 여부 예측을 위한 알고리즘으로는 의사 결정 트리를 이용하였고, 정확도는 70%를 웃돌았다. 정확도가 통상적 기준으로 높지 않은 이유는 데이터의 건수가 303건으로 많지 않기 때문이며 보다 다양한 유형의 환자들에 대한 데이터가 아니기 때문으로 추정된다. 그러나 심장 질환에 대한 변수들의 전반적인 특징과 영향을 살피기에는 다양한 수치가 포함된 표본이라고 할 수 있다.
심장 질환을 진단할 때 가장 영향도가 큰 변수는 지중해성 빈혈로 나타났으며 빈혈이 심할수록 심장 질환의 가능성이 80%로 높아졌다. 지중해성 빈혈을 제외한 심장 질환에 영향력이 높은 변수는 가슴 통증이었다. 지중해성 빈혈이 환자들의 거주지와 관련한 특이성이라고 하면 가슴 통증이 심장 질환을 판별하는 데에 가장 영향력 있는 변수라고 할 수 있다.
결론적으로 심장 질환에 영향을 미치는 변수는 지중해성 빈혈, 가슴 통증, 혈액 순환의 정도로 지중해성 빈혈이 심장 질환에 가장 큰 영향을 미치는 것으로 나타났으나, 이 질병은 지중해 연안이나 해역에 사는 환자들에게 나타나는 질병으로 심장 질환 분류에 적용할 만한 보편성은 없는 것으로 보인다. 그러나 가슴 통증이나 심혈관의 혈액 순환 정도를 관찰하는 것은 심장 질환을 판단하는 데에 의미 있는 변수로 확인되었다.
이런 글쓰는 연습을 충분히 한다면 좋은 데이터 분석가가 될 수 있을 것 같습니다.