
의사 결정트리로 독일 은행의 대출 채무 이행 여부를 분석해볼까합니다. 데이터는 여기에서 다운 받을 수 있습니다. 그리고 코드는 여기 GitHub에서 확인 할 수 있습니다.
DataSet
데이터 라벨은 default 변수이며, yes는 대출금 미상환, no는 대출금을 상환했다는 뜻입니다.
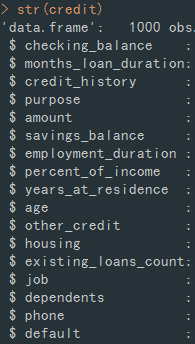
대부분의 컬럼은 이름에서부터 알 수 있기 때문에 다루진 않고, 알기 어려운 컬럼에 대해 설명을 조금 설명을 하자면 아래와 같습니다.
- checking_balance 예금 계좌
- savings_balance 적금 계좌
- amount 대출 금액
데이터에서 저 컬럼이 왜 있는지에 대해 분석을 조금 하게 되면, 데이터 분석시에 조금 수월할 수 있습니다. 예금계좌와 적금계좌가 있는 이유는 대출 신청자의 예금계좌와 적금계좌의 예금 정도를 확인해서 예금액이 많을수록 대출이 안전하다고 가정을 지을 수 있기 때문에 존재하는 컬럼입니다.
summary(credit$amount)
위와 같이 summary를 하게 되면 대출 금액의 구성도를 대충 파악 할 수 있습니다. 대출금액이 250 마르크에서 18424마르크로 구성되어 있음을 알 수 있습니다.
여기서 조금 더 나아가 대출금 상환을 한 사람과 안한사람의 비율을 잠깐 보면 아래와 같습니다.
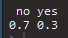
prop.table(table(credit$default))
70%정도가 대출금을 상환했다는 것을 알 수 있습니다.
과거 데이터를 분석해보니 대출금 상환 불이행자가 30%나 되니 앞으로 30%이내로 떨어트리는게 은행의 목표가 되겠금 model를 생성해보겠습니다.
우선 데이터를 shuffle 시키고 훈련데이터와 테스트 데이터를 9:1 비율로 나누겠습니다. 보통은 7:3 비율로 데이터를 나누지만, 어떤 비율을 할지는 자신의 선택이므로 다른 비율로 하셔도 괜찮습니다.
set.seed(1)
train_cnt <- round(0.9*dim(credit)[1])
train_index <- sample(1:dim(credit)[1], train_cnt, replace=F)
credit_train <- credit[train_index, ]
credit_test <- credit[-train_index, ]
또는
# train_cnt를 쓰지 않고
train_index <- sample(2, nrow(credit), prob=c(0.9, 0.1), replace=T)
credit_train <- credit[train_index==1, ]
credit_test <- credit[train_index==2, ]
C5.0 Model
의사 결정 알고리즘 중 C5.0 이라는 알고리즘을 적용하여 예측 모델을 생성해보겠습니다.
# 패키지 설치
install.packages("C50")
library(C50)
# 의사결정트리 C5.0 알고리즘을 적용한 모델 만들기
credit_model <- C50(credit_train[-17], credit_train[17])
# 라벨을 뺀 전체 컬럼 라벨 컬럼
그리고 모델을 적용하여 예측합니다.
credit_result <- predict(credit_model, credit_test)
이번엔 위에서 만든 결과를 사용하여 이원 교차표를 작성하겠습니다.
library(gmodels)
CrossTable(credit_result, credit_test[, 17])
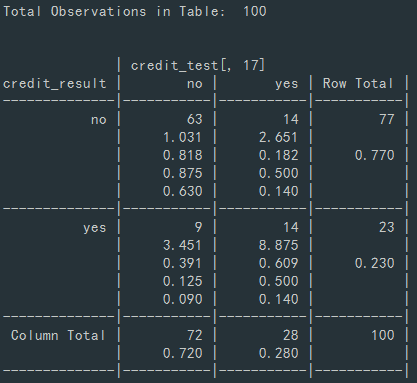
표를 보면 알 수 있듯이 채무 이행을 안했는데, 채무 이행을 했다고 나온 경우를 볼 수 있습니다. 채무 이행으로 나왔으나 불이행한 사람이 14명이나 있었으므로 정확도를 올리고 오류율 14명을 줄일 수 있도록 모델의 성능을 올려보겠습니다.
앙상블
credit_model2 <- C5.0(credit_train[,-17], credit_train[,17], trials=10)
credit_result2 <- predict(credit_model2, credit_test[,-17])
CrossTable(credit_result2, credit_test[, 17])
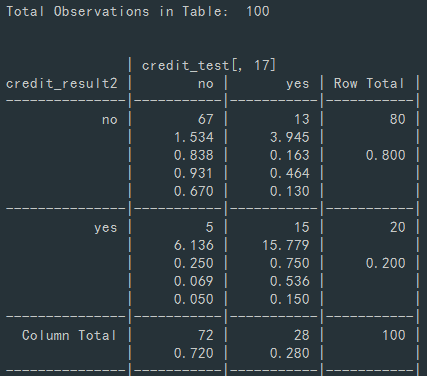
성능이 월등하게 개선되진 않았지만, 결정 트리 하나의 모델로만으로도 성능을 개선할 수 있음을 알 수 있었습니다.
여기서 만약 성능 개선을 더 해보고 싶다면, 아래와 같이 앙상블을 이용하여 모델을 개선할 수 있습니다. (앙상블에 대한 자세한 설명은 다음에..)
install.packages("caret")
library(caret)
set.seed(300)
m <- train(default ~., data = credit , method = "C5.0" )
p<-predict(m, credit)
table(p, credit$default)
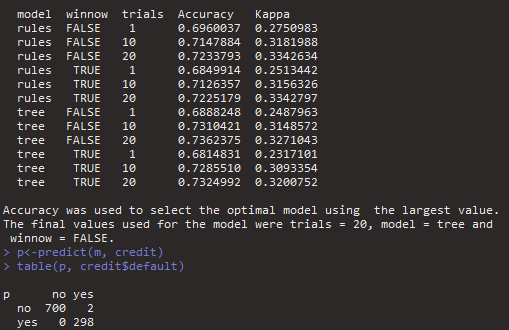
정확도 99.8%까지 올릴 수 있음을 알 수 있습니다.