
우선은 병렬처리를 왜하는걸까? 병렬처리가 중요한가 ?와 함께 하둡에 대해 살짝 이야기 해볼까한다. 하둡(hadoop)이라고 아마 많이 들어봤을꺼다. 구글에서 쌓여지는 수많은 빅데이터들을 구글에서도 처음에는 RDBMS(오라클)에 입력하고 데이터를 저장하고 처리하려고 시도를 했지만, 데이터가 너무 많아서 실패하고 자체적으로 빅데이터를 저장할 기술을 개발했다. 그리고 대외적으로 논문 하나를 발표했는데, 그 논문을 더그커팅이라는 사람이 읽고 자바로 구현한게 하둡(hadoop)이다.
여기서 TMI는 이름을 뭘로 할까 고민하다가 더그커팅의 애기가 노란 코키리 장난감을 가지고 그냥 Hadoop이라고 하는걸 듣고 하둡이라고 이름을 지었다고 한다.
아무튼 병렬처리는 여러대의 노드를 묶어서 마치 하나의 서버처럼 보이게하고 여러 노드의 자원을 이용해서 데이터를 처리하기 때문에 처리하는 속도가 아주 빠르다는 장점이 있다.
Hadoop
여기서 TMI는 이름을 뭘로 할까 고민하다가 더그커팅의 아이가 노란 코키리 장난감을 가지고 놀면서 그냥 Hadoop이라고 하는걸 듣고 하둡이라고 이름을 지었다고 한다.
아무튼 병렬처리는 여러대의 노드를 묶어서 마치 하나의 서버처럼 보이게하고 여러 노드의 자원을 이용해서 데이터를 처리하기 때문에 처리하는 속도가 아주 빠르다는 장점이 있다.
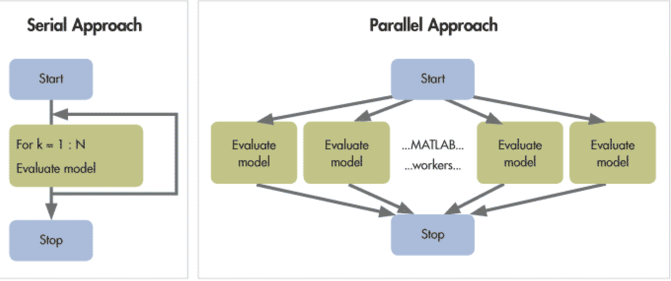
현대의 서버로 1테라 바이트의 데이터를 처리하는데 걸리는 시간은 2시간 반이 걸린다고 하면 병렬처리로 작업을 하면 2분내에 데이터를 읽을 수 있다. 사실 하둡이 사용하는 것이 좋지만 우선 R에서 사용할 수 있는 간단한 병렬처리를 코드를 작성해볼까한다.
snow함수를 이용한 병렬처리
병렬처리는 여러가지 방법으로 할 수 있는데, 아래는 snow를 이용한 병렬처리 예제이다.
install.packages("snow")
library(snow)
ex.df <- data.frame(a=seq(1,100000,1),b=seq(10,1000000,10),c=runif(10000))
custom.function <- function(a,b,c){
result <- (a+b)*c
return(result)
}
system.time(apply(ex.df,1, function(x) custom.function(x[1],x[2],x[3])))
clus <- makeCluster(3)
clusterEvalQ(clus, custom.function <- function(a,b,c){
result <- (a+b)*c
return(result)})
clusterExport(clus,"custom.function")
system.time(parRapply(clus,ex.df, function(x) custom.function(x[1],x[2],x[3])))
ClusterEval는 snow 에서 함수 선언할때 사용하는 함수이다.
foreach함수를 이용한 병렬처리
또 다른 패키지인 foreach를 사용하여 병렬처리를 해볼까한다.
install.packages("foreach")
library(foreach)
system.time(l1 <- rnorm(100000000))
system.time(l4 <- foreach(i = 1:4, .combine = 'c') %do% rnorm(25000000))
먼가 코드가 점점 짧아지는거 같다.
doParallel함수를 이용한 병렬처리
마지막으로 doParallel를 사용하여 병렬처리 하는 방법은 아래와 같다.
install.packages("doRarallel")
library(doParallel)
registerDoParallel(cores=4)
system.time(l4p <- foreach(i = 1:4, .combine = 'c') %dopar% rnorm(25000000))